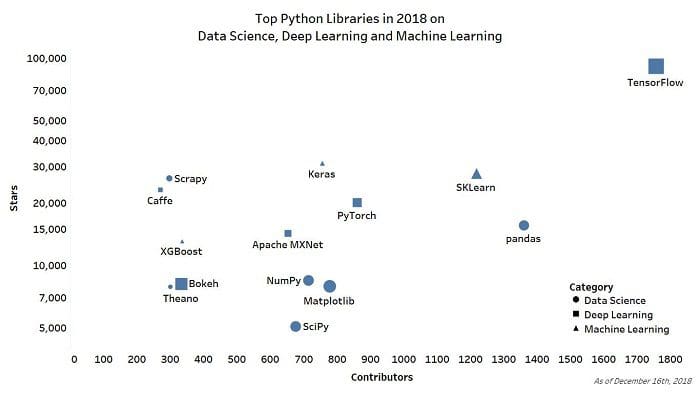
Top Python Libraries in 2018 in Data Science, Deep Learning, Machine Learning
Here are the top 15 Python libraries across Data Science, Data Visualization. Deep Learning, and Machine Learning.
We recently published a series of articles looking at the top Python libraries, across Data science, Deep Learning and Machine Learning. As the year draws to a close, we thought we’d give you a special Christmas gift, and collate these into a KDnuggets official top Python libraries in 2018.
As always, we want your opinions! So, if you think we’ve unfairly left any out, or if you disagree with any of our choices, please let us know in the comments section below.
Fig. 1: Top Python Libraries, by GitHub Stars and Contributors. Shape size is proportional to number of commits.
So here it is, our top 15 Python Libraries in 2018 (all figures correct as of December 16th, 2018):
1 – TensorFlow (Contributors – 1757, Commits – 25756, Stars – 116765)
“TensorFlow is an open source software library for numerical computation using data flow graphs. The graph nodes represent mathematical operations, while the graph edges represent the multidimensional data arrays (tensors) that flow between them. This flexible architecture enables you to deploy computation to one or more CPUs or GPUs in a desktop, server, or mobile device without rewriting code. “
2 – pandas (Contributors – 1360, Commits – 18441, Stars – 17388)
“pandas is a Python package providing fast, flexible, and expressive data structures designed to make working with “relational” or “labeled” data both easy and intuitive. It aims to be the fundamental high-level building block for doing practical, real world data analysis in Python.”
3 – scikit-learn (Contributors – 1218, Commits – 23509, Stars – 32326)
“scikit-learn is a Python module for machine learning built on NumPy, SciPy and matplotlib. It provides simple and efficient tools for data mining and data analysis. SKLearn is accessible to everybody and reusable in various contexts.
4 – PyTorch (Contributors – 861, Commits – 15362, Stars – 22763)
“PyTorch is a Python package that provides two high-level features:
- Tensor computation (like NumPy) with strong GPU acceleration
- Deep neural networks built on a tape-based autograd system
You can reuse your favorite Python packages such as NumPy, SciPy and Cython to extend PyTorch when needed.”
5 – Matplotlib (Contributors – 778, Commits – 28094, Stars – 8362)
“Matplotlib is a Python 2D plotting library which produces publication-quality figures in a variety of hardcopy formats and interactive environments across platforms. Matplotlib can be used in Python scripts, the Python and IPython shell (à la MATLAB or Mathematica), web application servers, and various graphical user interface toolkits.”
6 – Keras (Contributors – 856, Commits – 4936, Stars – 36450)
“Keras is a high-level neural networks API, written in Python and capable of running on top of TensorFlow, CNTK, or Theano. It was developed with a focus on enabling fast experimentation. Being able to go from idea to result with the least possible delay is key to doing good research.”
7 – NumPy (Contributors – 714, Commits – 19399, Stars – 9010)
“NumPy is the fundamental package needed for scientific computing with Python. It provides a powerful N-dimensional array object, sophisticated (broadcasting) functions, tools for integrating C/C++ and Fortran code and useful linear algebra, Fourier transform, and random number capabilities.”
8 – SciPy (Contributors – 676, Commits – 20180, Stars – 5188)
“SciPy (pronounced “Sigh Pie”) is open-source software for mathematics, science, and engineering. It includes modules for statistics, optimization, integration, linear algebra, Fourier transforms, signal and image processing, ODE solvers, and more.”
9 – Apache MXNet (Contributors – 653, Commits – 9060, Stars – 15812)
“Apache MXNet (incubating) is a deep learning framework designed for both efficiency and flexibility. It allows you to mixsymbolic and imperative programming to maximize efficiency and productivity. At its core, MXNet contains a dynamic dependency scheduler that automatically parallelizes both symbolic and imperative operations on the fly.”
10 – Theano (Contributors – 333, Commits – 28060, Stars – 8614)
“Theano is a Python library that allows you to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. It can use GPUs and perform efficient symbolic differentiation.”
11 – Bokeh (Contributors – 334, Commits – 17395, Stars – 8649)
“Bokeh is an interactive visualization library for Python that enables beautiful and meaningful visual presentation of data in modern web browsers. With Bokeh, you can quickly and easily create interactive plots, dashboards, and data applications.”
12 – XGBoost (Contributors – 335, Commits – 3557, Stars – 14389)
“XGBoost is an optimized distributed gradient boosting library designed to be highly efficient</strong, flexible and portable. It implements machine learning algorithms under the Gradient Boosting framework. XGBoost provides a parallel tree boosting (also known as GBDT, GBM) that solve many data science problems in a fast and accurate way. The same code runs on major distributed environment (Hadoop, SGE, MPI) and can solve problems beyond billions of examples.”
13 – Gensim (Contributors – 301, Commits – 3687, Stars – 8295)
“Gensim is a Python library for topic modelling, document indexing and similarity retrieval with large corpora. Target audience is the natural language processing (NLP) and information retrieval (IR) community.”
14 – Scrapy (Contributors – 297, Commits – 6808, Stars – 30507)
“Scrapy is a fast high-level web crawling and web scraping framework, used to crawl websites and extract structured data from their pages. It can be used for a wide range of purposes, from data mining to monitoring and automated testing.”
15 – Caffe (Contributors – 270, Commits – 4152, Stars – 26531)
“Caffe is a deep learning framework made with expression, speed, and modularity in mind. It is developed by Berkeley AI Research (BAIR)/The Berkeley Vision and Learning Center (BVLC) and community contributors.”
Source: Top Python Libraries in 2018 in Data Science, Deep Learning, Machine Learning
Related Blogs:
Transforming Enterprises with
Data & AI Services & Solutions.
ThirdEye delivers Data and AI services & solutions for enterprises worldwide by
leveraging state-of-the-art Data & AI technologies.




