Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams. Spark Streaming can be used to stream live data and processing can happen in real time. Spark Streaming’s ever-growing user base consists of household names like Uber, Netflix and Pinterest.When it comes to Real Time Data Analytics, Spark Streaming provides a single platform to ingest data for fast and live processing in Apache Spark. Through this blog, I will introduce you to this new exciting domain of Spark Streaming and we will go through a complete use case, Twitter Sentiment Analysis using Spark Streaming.
Data Streaming is a technique for transferring data so that it can be processed as a steady and continuous stream. Streaming technologies are becoming increasingly important with the growth of the Internet.
We can use Spark Streaming to stream real-time data from various sources like Twitter, Stock Market and Geographical Systems and perform powerful analytics to help businesses.
Spark Streaming is used for processing real-time streaming data. It is a useful addition to the core Spark API. Spark Streaming enables high-throughput and fault-tolerant stream processing of live data streams.
 Figure: Streams in Spark Streaming
Figure: Streams in Spark Streaming
The fundamental stream unit is DStream which is basically a series of RDDs to process the real-time data.
Spark Streaming Workflow
Spark Streaming workflow has four high-level stages. The first is to stream data from various sources. These sources can be streaming data sources like Akka, Kafka, Flume, AWS or Parquet for real-time streaming. The second type of sources includes HBase, MySQL, PostgreSQL, Elastic Search, Mongo DB and Cassandra for static/batch streaming. Once this happens, Spark can be used to perform Machine Learning on the data through its MLlib API. Further, Spark SQL is used to perform further operations on this data. Finally, the streaming output can be stored into various data storage systems like HBase, Cassandra, MemSQL, Kafka, Elastic Search, HDFS and local file system.
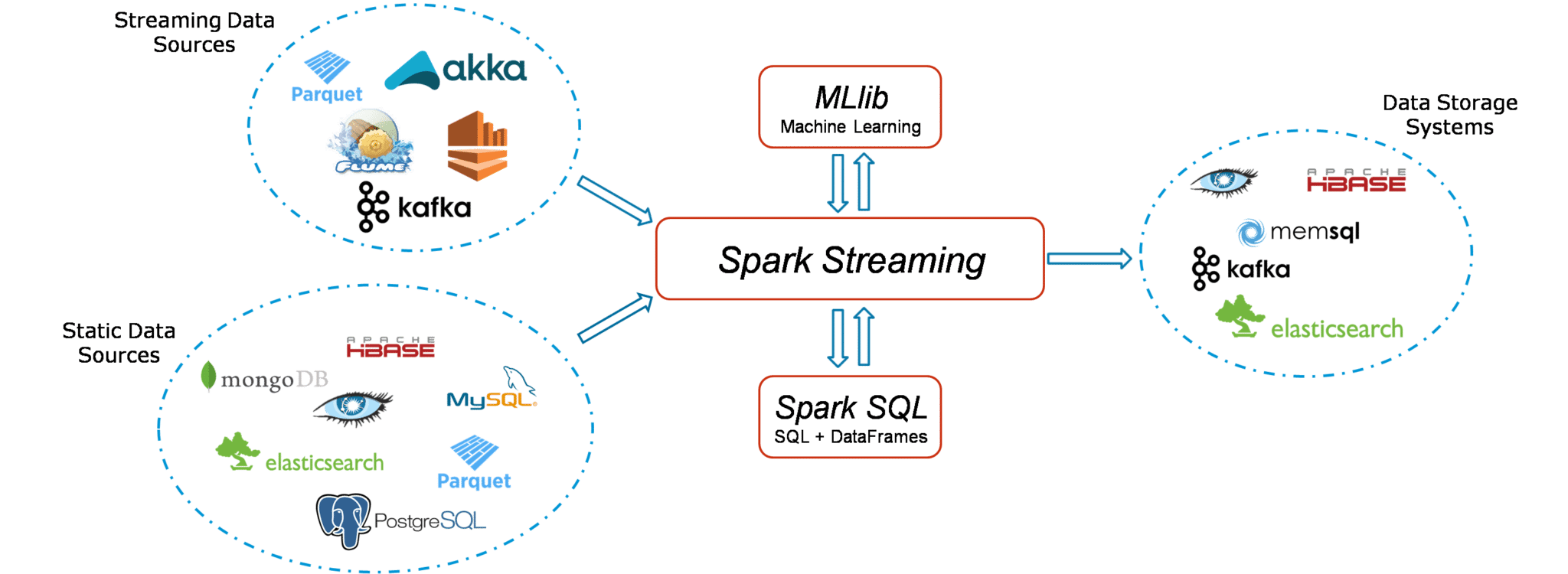
Figure: Overview Of Spark Streaming
Streaming Context
Streaming Context consumes a stream of data in Spark. It registers an Input DStream to produce a Receiverobject. It is the main entry point for Spark functionality. Spark provides a number of default implementations of sources like Twitter, Akka Actor and ZeroMQ that are accessible from the context.
 A StreamingContext object can be created from a SparkContext object. A SparkContext represents the connection to a Spark cluster and can be used to create RDDs, accumulators and broadcast variables on that cluster.
A StreamingContext object can be created from a SparkContext object. A SparkContext represents the connection to a Spark cluster and can be used to create RDDs, accumulators and broadcast variables on that cluster.
|
1
2
3
|
import org.apache.spark._import org.apache.spark.streaming._var ssc = new StreamingContext(sc,Seconds(1)) |
DStream
Discretized Stream (DStream) is the basic abstraction provided by Spark Streaming. It is a continuous stream of data. It is received from a data source or a processed data stream generated by transforming the input stream.
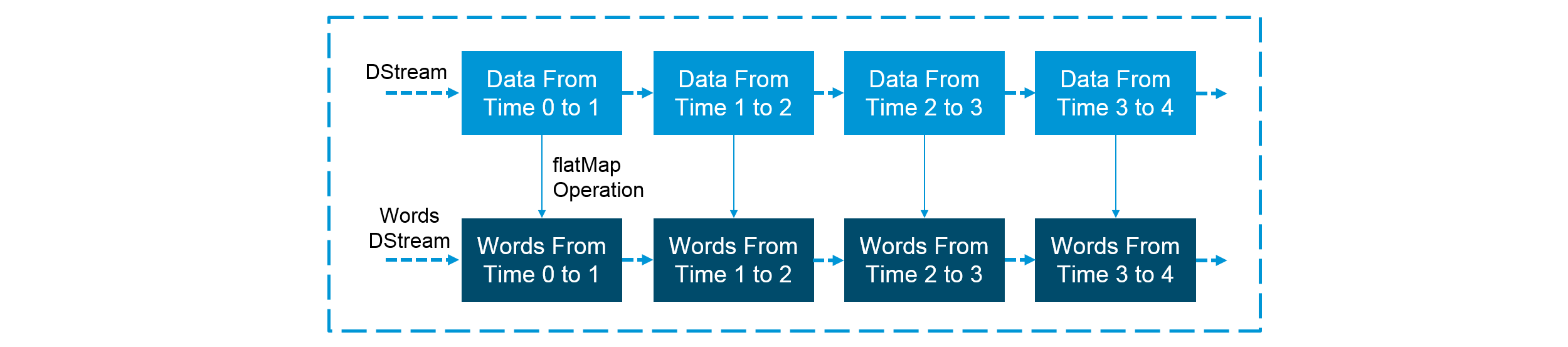 Figure: Extracting words from an Input DStream
Figure: Extracting words from an Input DStream
Internally, a DStream is represented by a continuous series of RDDs and each RDD contains data from a certain interval.
Input DStreams: Input DStreams are DStreams representing the stream of input data received from streaming sources.
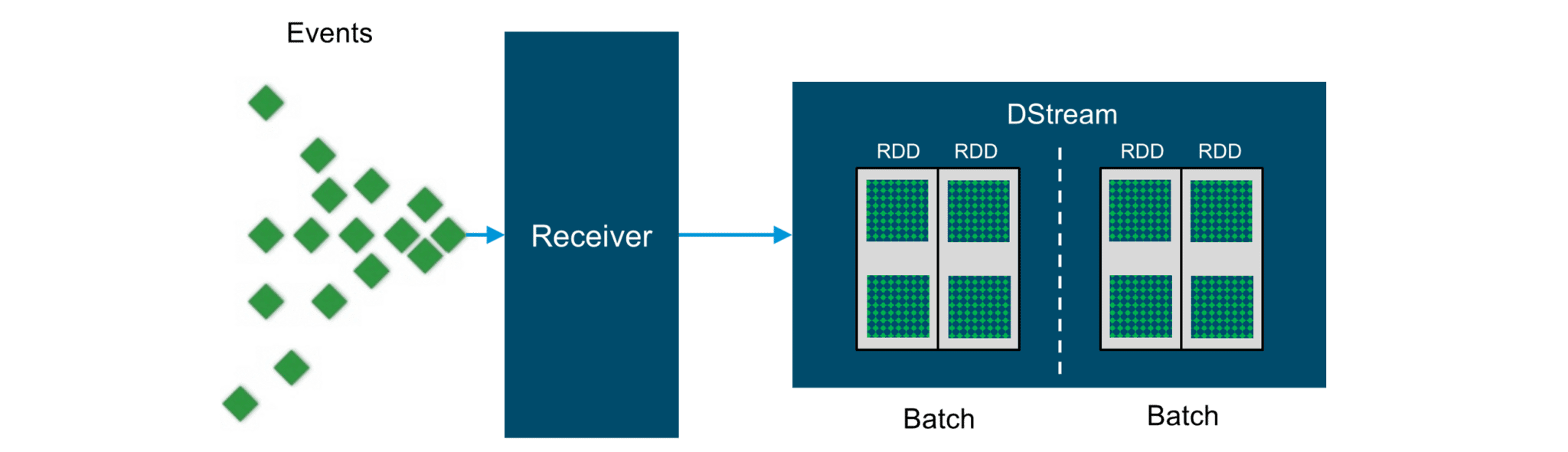 Figure: The Receiver sends data onto the Input DStream where each Batch contains RDDs
Figure: The Receiver sends data onto the Input DStream where each Batch contains RDDs
Every input DStream is associated with a Receiver object which receives the data from a source and stores it in Spark’s memory for processing.
Transformations on DStreams:
Any operation applied on a DStream translates to operations on the underlying RDDs. Transformations allow the data from the input DStream to be modified similar to RDDs. DStreams support many of the transformations available on normal Spark RDDs.
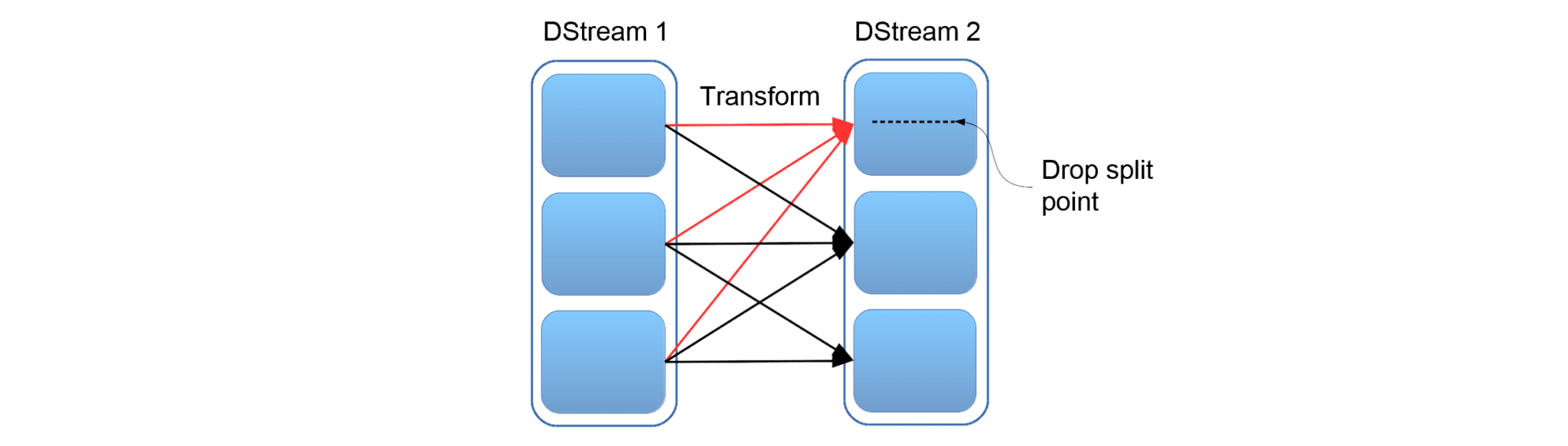 Figure: DStream Transformations
Figure: DStream Transformations
The following are some of the popular transformations on DStreams:
| map(func) | map(func) returns a new DStream by passing each element of the source DStream through a function func. |
| flatMap(func) | flatMap(func) is similar to map(func) but each input item can be mapped to 0 or more output items and returns a new DStream by passing each source element through a function func. |
| filter(func) | filter(func) returns a new DStream by selecting only the records of the source DStream on which func returns true. |
| reduce(func) | reduce(func) returns a new DStream of single-element RDDs by aggregating the elements in each RDD of the source DStream using a function func. |
| groupBy(func) | groupBy(func) returns the new RDD which basically is made up with a key and corresponding list of items of that group. |
Output DStreams:
Output operations allow DStream’s data to be pushed out to external systems like databases or file systems. Output operations trigger the actual execution of all the DStream transformations.
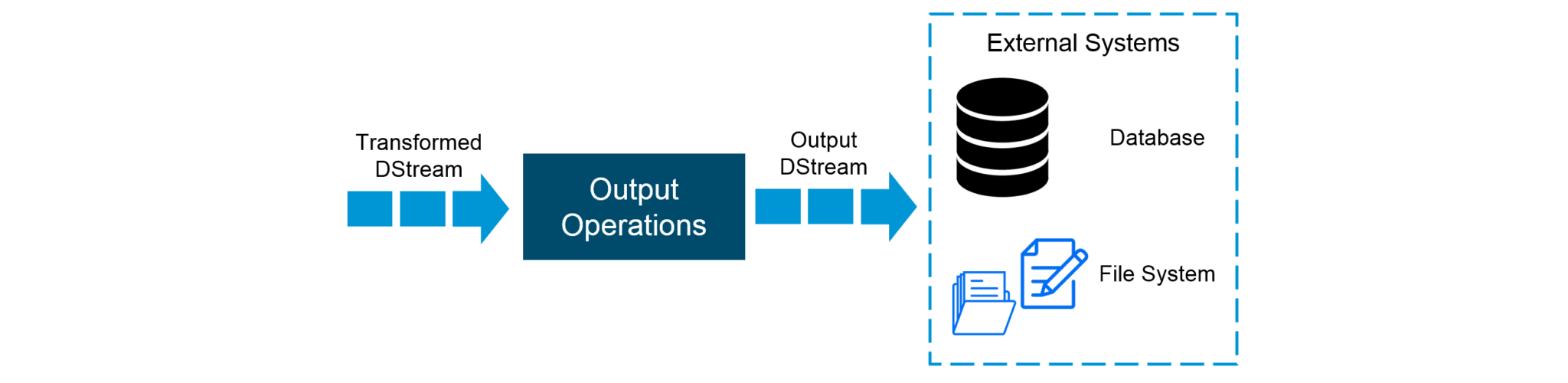 Figure: Output Operations on DStreams
Figure: Output Operations on DStreams
Caching
DStreams allow developers to cache/ persist the stream’s data in memory. This is useful if the data in the DStream will be computed multiple times. This can be done using the persist() method on a DStream.
 Figure: Caching into 2 Nodes
Figure: Caching into 2 Nodes
For input streams that receive data over the network (such as Kafka, Flume, Sockets, etc.), the default persistence level is set to replicate the data to two nodes for fault-tolerance.
Accumulators, Broadcast Variables and Checkpoints
Accumulators: Accumulators are variables that are only added through an associative and commutative operation. They are used to implement counters or sums. Tracking accumulators in the UI can be useful for understanding the progress of running stages. Spark natively supports numeric accumulators. We can create named or unnamed accumulators.
Broadcast Variables: Broadcast variables allow the programmer to keep a read-only variable cached on each machine rather than shipping a copy of it with tasks. They can be used to give every node a copy of a large input dataset in an efficient manner. Spark also attempts to distribute broadcast variables using efficient broadcast algorithms to reduce communication cost.
Checkpoints: Checkpoints are similar to checkpoints in gaming. They make it run 24/7 and make it resilient to failures unrelated to the application logic.
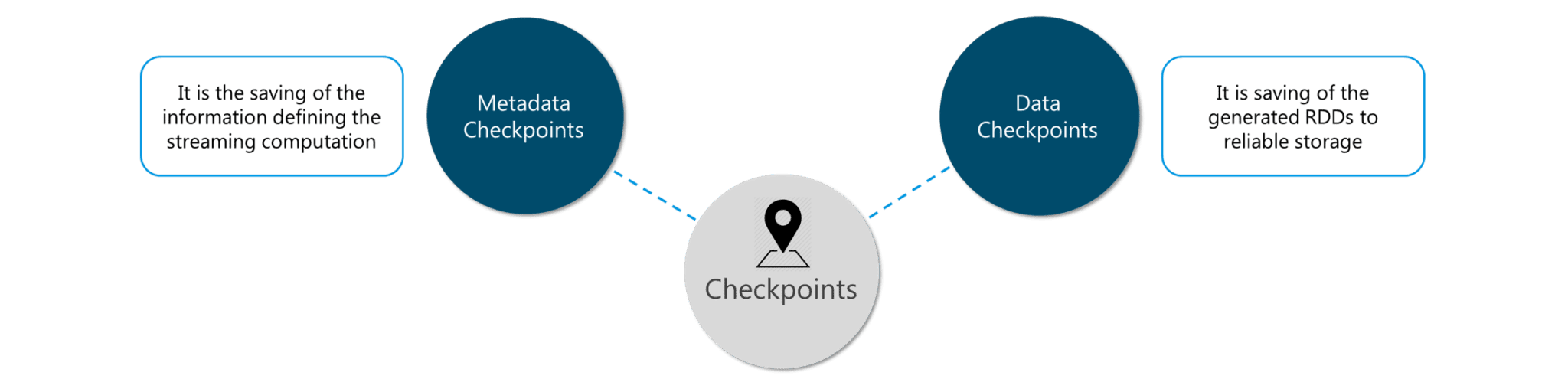
Figure: Features of Checkpoints
Now that we have understood the core concepts of Spark Streaming, let us solve a real-life problem using Spark Streaming.
Problem Statement: To design a Twitter Sentiment Analysis System where we populate real-time sentiments for crisis management, service adjusting and target marketing.
Applications of Sentiment Analysis:
Spark Streaming Implementation:
Find the Pseudo Code below:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
|
//Import the necessary packages into the Spark Programimport org.apache.spark.streaming.{Seconds, StreamingContext}import org.apache.spark.SparkContext._...import java.io.Fileobject twitterSentiment {def main(args: Array[String]) {if (args.length < 4) {System.err.println("Usage: TwitterPopularTags <consumer key> <consumer secret> " + "<access token> <access token secret> [<filters>]")System.exit(1)}StreamingExamples.setStreamingLogLevels()//Passing our Twitter keys and tokens as arguments for authorizationval Array(consumerKey, consumerSecret, accessToken, accessTokenSecret) = args.take(4)val filters = args.takeRight(args.length - 4)// Set the system properties so that Twitter4j library used by twitter stream// Use them to generate OAuth credentialsSystem.setProperty("twitter4j.oauth.consumerKey", consumerKey)...System.setProperty("twitter4j.oauth.accessTokenSecret", accessTokenSecret)val sparkConf = new SparkConf().setAppName("twitterSentiment").setMaster("local[2]")val ssc = new Streaming Contextval stream = TwitterUtils.createStream(ssc, None, filters)//Input DStream transformation using flatMapval tags = stream.flatMap { status => Get Text From The Hashtags }//RDD transformation using sortBy and then map functiontags.countByValue().foreachRDD { rdd =>val now = Get current time of each Tweetrdd.sortBy(_._2).map(x => (x, now))//Saving our output at ~/twitter/ directory.saveAsTextFile(s"~/twitter/$now")}//DStream transformation using filter and map functionsval tweets = stream.filter {t =>val tags = t. Split On Spaces .filter(_.startsWith("#")). Convert To Lower Casetags.exists { x => true }}val data = tweets.map { status =>val sentiment = SentimentAnalysisUtils.detectSentiment(status.getText)val tagss = status.getHashtagEntities.map(_.getText.toLowerCase)(status.getText, sentiment.toString, tagss.toString())}data.print()//Saving our output at ~/ with filenames starting like twittersdata.saveAsTextFiles("~/twitters","20000")ssc.start()ssc.awaitTermination() }} |
Click here to get the full source code of Twitter Sentiment Analysis using Spark Streaming.
Results:
The following are the results that are displayed in the Eclipse IDE while running the Twitter Sentiment Streaming program.
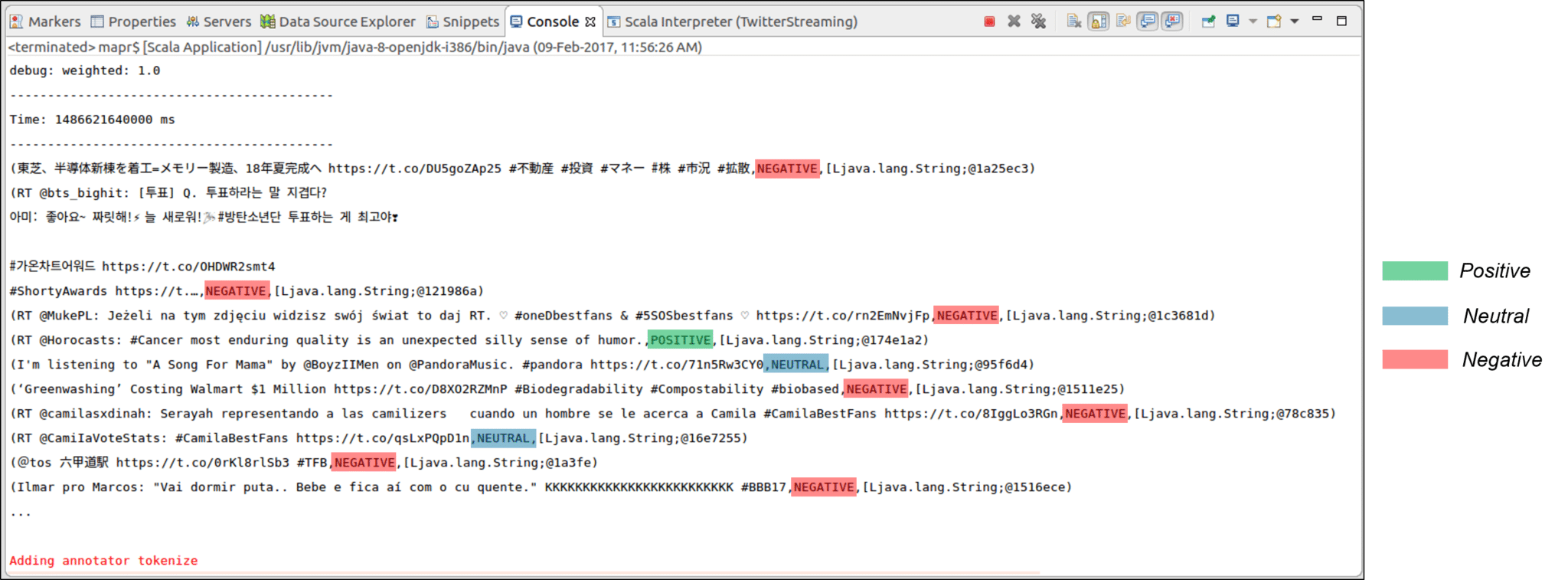
Figure: Sentiment Analysis Output in Eclipse IDE
As we can see in the screenshot, all the tweets are categorized into Positive, Neutral and Negative according to the sentiment of the contents of the tweets.
The output of the Sentiments of the Tweets is stored into folders and files according to the time they were created. This output can be stored on the local file system or HDFS as necessary. The output directory looks like this:
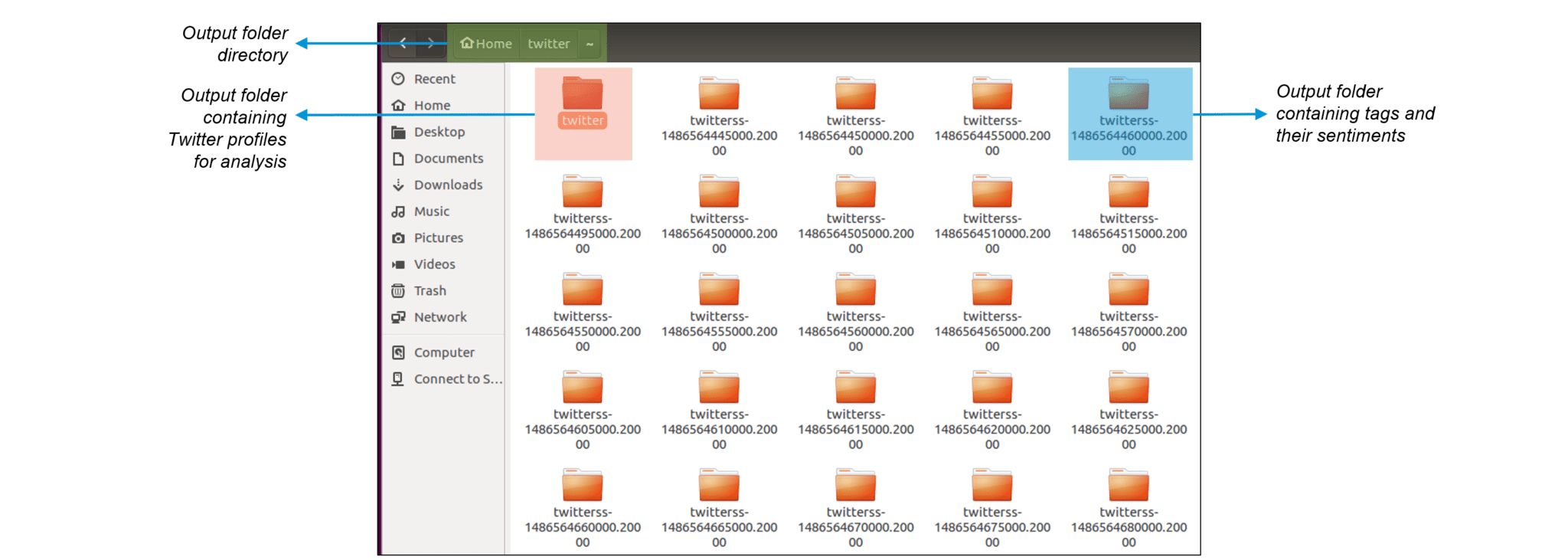 Figure: Output folders inside our ‘twitter’ project folder
Figure: Output folders inside our ‘twitter’ project folder
Here, inside the twitter directory, we can find the usernames of the Twitter users along with the timestamp for every tweet as shown below:
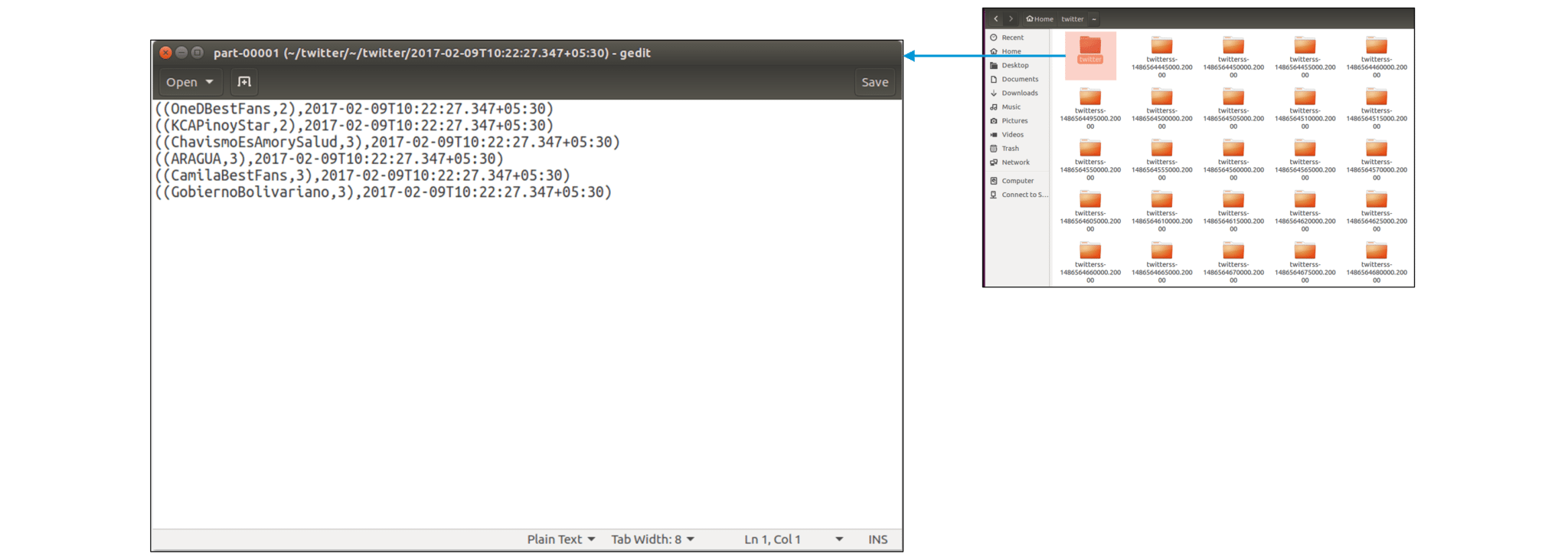 Figure: Output file containing Twitter usernames with timestamp
Figure: Output file containing Twitter usernames with timestamp
Now that we have got the Twitter usernames and timestamp, let us look at the Sentiments and tweets stored in the main directory. Here, every tweet is followed by the sentiment emotion. This Sentiment that is stored is further used for analyzing a vast multitude of insights by companies.
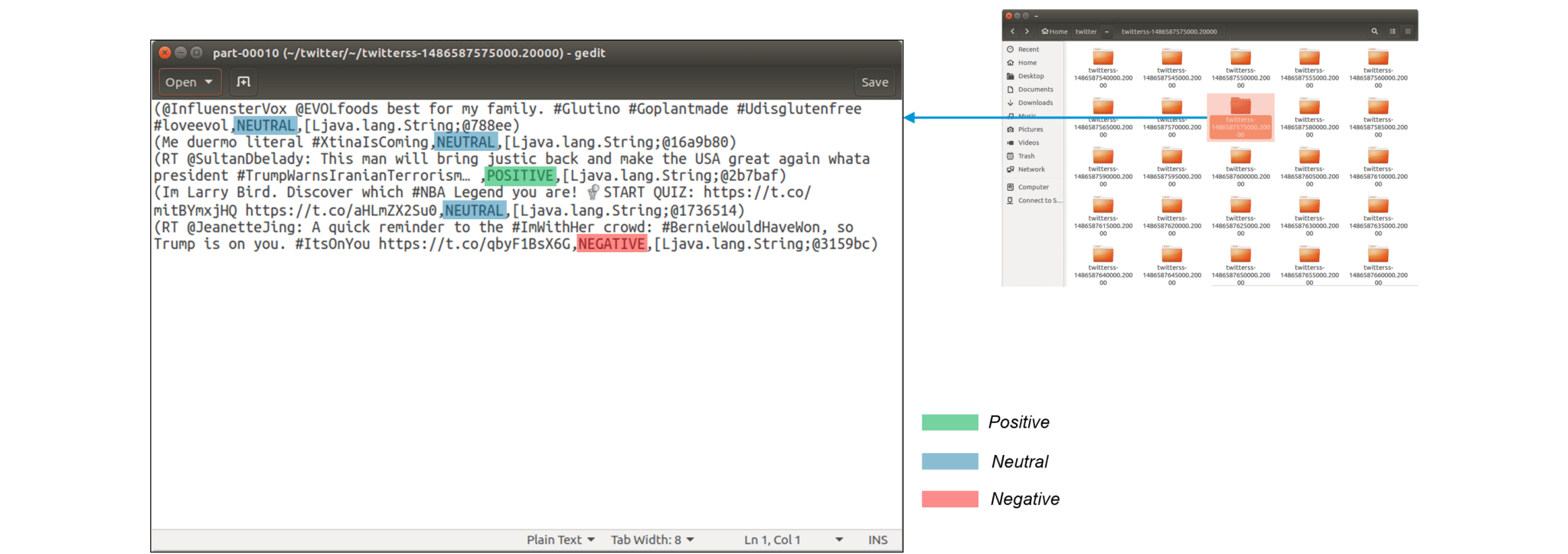 Figure: Output file containing tweets with sentiments
Figure: Output file containing tweets with sentiments
Tweaking Code:
Now, let us modify our code a little to get sentiments for specific hashtags (topics). Currently, Donald Trump, the President of the United States is trending across news channels and online social media. Let us look at the sentiments associated with the keyword ‘Trump‘.
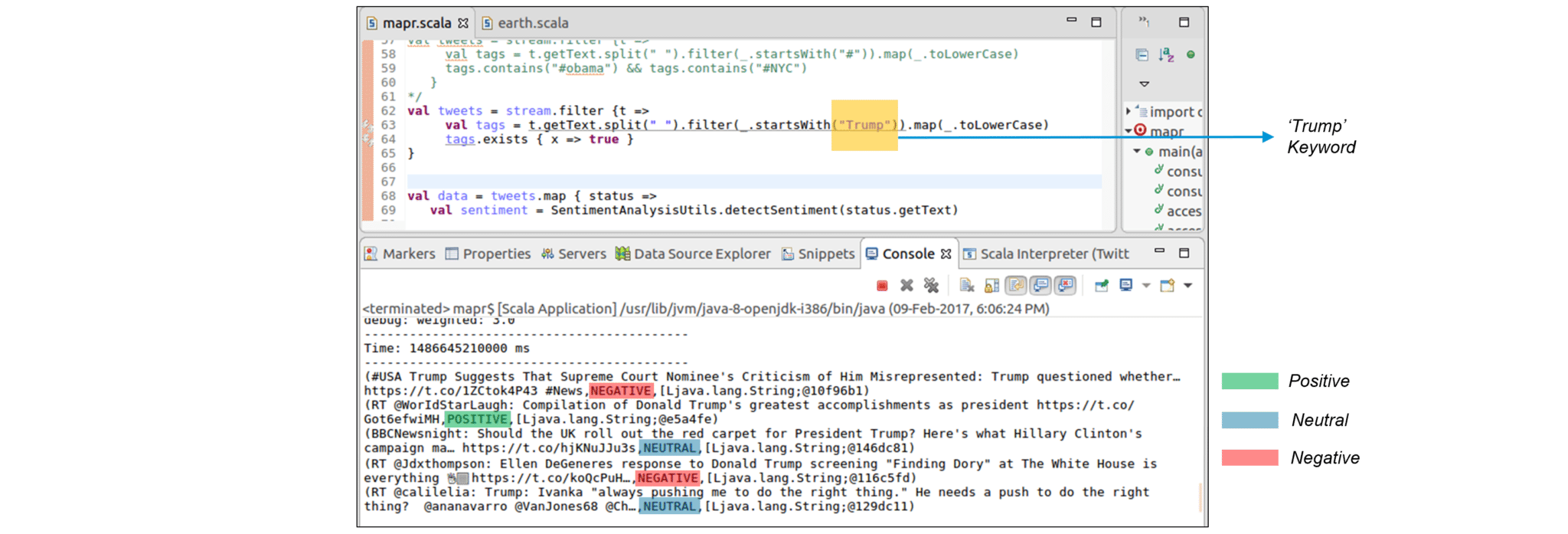 Figure: Performing Sentiment Analysis on Tweets with ‘Trump’ Keyword
Figure: Performing Sentiment Analysis on Tweets with ‘Trump’ Keyword
Source: Spark Streaming Tutorial | Twitter Sentiment Analysis Using Apache Spark | Edureka

Transforming Enterprises with
Data & AI Services & Solutions.
ThirdEye delivers Data and AI services & solutions for enterprises worldwide by
leveraging state-of-the-art Data & AI technologies.