Apache Spark is a lightning-fast cluster computing framework designed for fast computation. It is of the most successful projects in the Apache Software Foundation. Spark SQL is a new module in Spark which integrates relational processing with Spark’s functional programming API. It supports querying data either via SQL or via the Hive Query Language.
Spark SQL originated as Apache Hive to run on top of Spark and is now integrated with the Spark stack. Apache Hive had certain limitations as mentioned below. Spark SQL was built to overcome these drawbacks and replace Apache Hive.
These drawbacks gave way to the birth of Spark SQL.
Spark SQL integrates relational processing with Spark’s functional programming. It provides support for various data sources and makes it possible to weave SQL queries with code transformations thus resulting in a very powerful tool.
Let us explore, what Spark SQL has to offer. Spark SQL blurs the line between RDD and relational table. It offers much tighter integration between relational and procedural processing, through declarative DataFrame APIs which integrates with Spark code. It also provides higher optimization. DataFrame API and Datasets API are the ways to interact with Spark SQL.
With Spark SQL, Apache Spark is accessible to more users and improves optimization for the current ones. Spark SQL provides DataFrame APIs which perform relational operations on both external data sources and Spark’s built-in distributed collections. It introduces extensible optimizer called Catalyst as it helps in supporting a wide range of data sources and algorithms in Big-data.
Spark runs on both Windows and UNIX-like systems (e.g. Linux, Microsoft, Mac OS). It is easy to run locally on one machine — all you need is to have java installed on your system PATH, or the JAVA_HOME environment variable pointing to a Java installation.
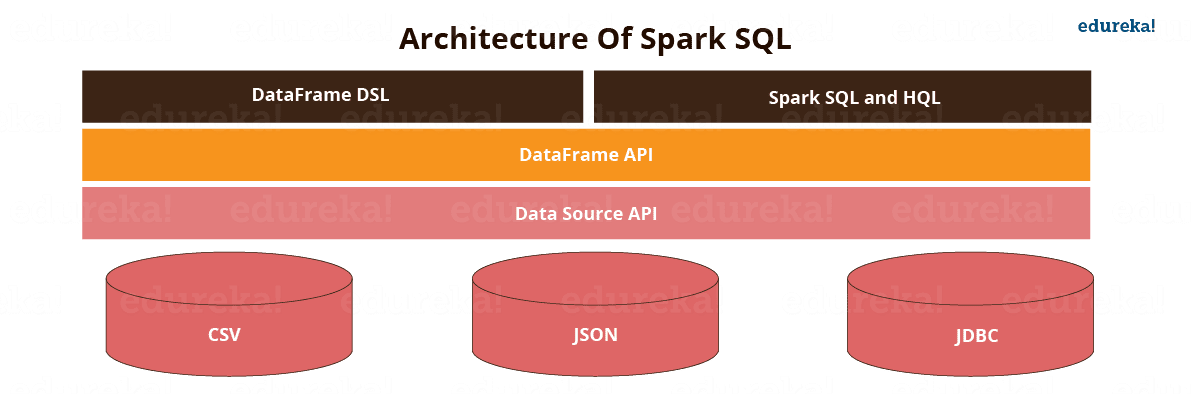
Figure: Architecture of Spark SQL.
Spark SQL has the following four libraries which are used to interact with relational and procedural processing:
This is a universal API for loading and storing structured data.
A DataFrame is a distributed collection of data organized into named column. It is equivalent to a relational table in SQL used for storing data into tables.
SQL Interpreter and Optimizer is based on functional programming constructed in Scala.
e.g. Catalyst is a modular library which is made as a rule based system. Each rule in framework focuses on the distinct optimization.
SQL Service is the entry point for working with structured data in Spark. It allows the creation of DataFrame objects as well as the execution of SQL queries.
The following are the features of Spark SQL:
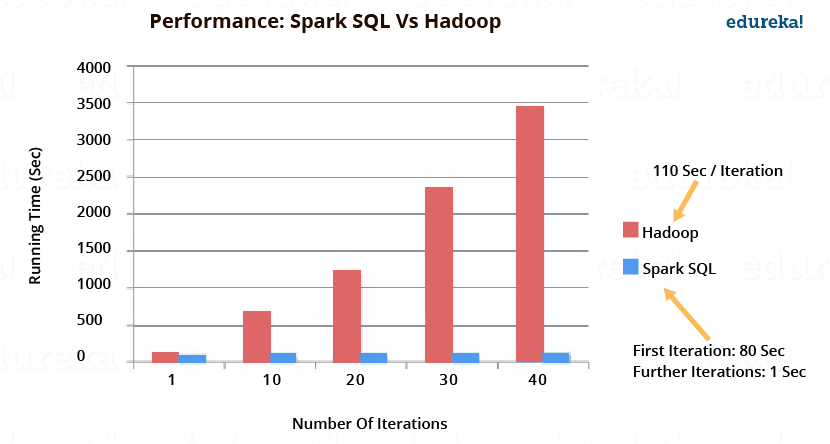
The image below depicts the performance of Spark SQL when compared to Hadoop. Spark SQL executes upto 100x times faster than Hadoop.
The example below defines a UDF to convert a given text to upper case.
Code explanation:
1. Creating a dataset “hello world”
2. Defining a function ‘upper’ which converts a string into upper case.
3. We now import the ‘udf’ package into Spark.
4. Defining our UDF, ‘upperUDF’ and importing our function ‘upper’.
5. Displaying the results of our User Defined Function in a new column ‘upper’.
|
1
2
3
4
5
|
val dataset = Seq((0, "hello"),(1, "world")).toDF("id","text")val upper: String => String =_.toUpperCaseimport org.apache.spark.sql.functions.udfval upperUDF = udf(upper)dataset.withColumn("upper", upperUDF('text)).show |
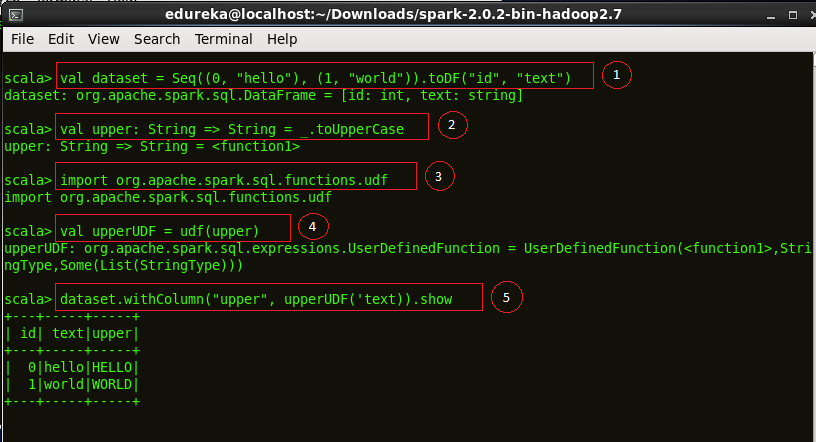 Figure:Demonstration of a User Defined Function, upperUDF
Figure:Demonstration of a User Defined Function, upperUDF
Code explanation:
1. We now register our function as ‘myUpper’
2. Cataloging our UDF among the other functions.
|
1
2
|
spark.udf.register("myUpper", (input:String) => input.toUpperCase)spark.catalog.listFunctions.filter('name like "%upper%").show(false) |
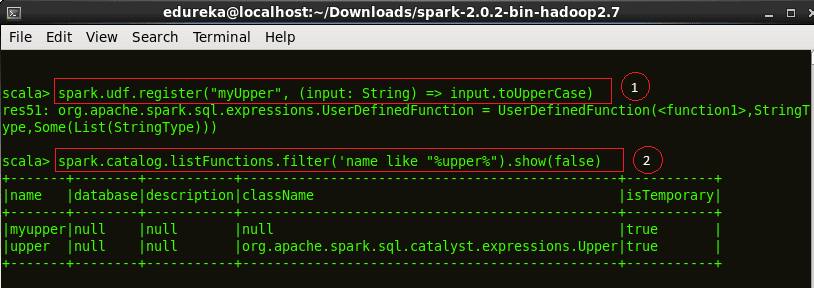 Figure:Results of the User Defined Function, upperUDF
Figure:Results of the User Defined Function, upperUDF
We will now start querying using Spark SQL. Note that the actual SQL queries are similar to the ones used in popular SQL clients.
Starting the Spark Shell. Go to the Spark directory and execute ./bin/spark-shell in the terminal to being the Spark Shell.
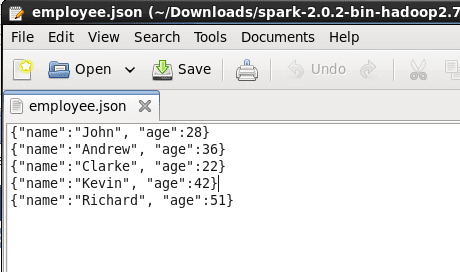
For the querying examples shown in the blog, we will be using two files, ’employee.txt’ and ’employee.json’. The images below show the content of both the files. Both these files are stored at ‘examples/src/main/scala/org/apache/spark/examples/sql/SparkSQLExample.scala’ inside the folder containing the Spark installation (~/Downloads/spark-2.0.2-bin-hadoop2.7). So, all of you who are executing the queries, place them in this directory or set the path to your files in the lines of code below.
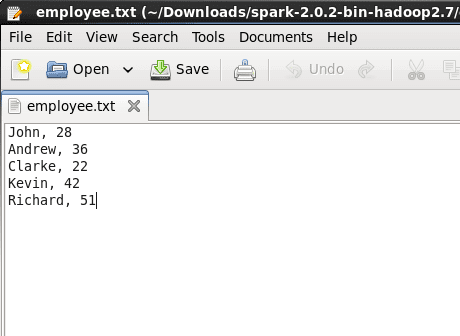
Figure:Contents of employee.txt
Code explanation:
1. We first import a Spark Session into Apache Spark.
2. Creating a Spark Session ‘spark’ using the ‘builder()’ function.
3. Importing the Implicts class into our ‘spark’ Session.
4. We now create a DataFrame ‘df’ and import data from the ’employee.json’ file.
5. Displaying the DataFrame ‘df’. The result is a table of 5 rows of ages and names from our ’employee.json’ file.
|
1
2
3
4
5
|
import org.apache.spark.sql.SparkSessionval spark = SparkSession.builder().appName("Spark SQL basic example").config("spark.some.config.option", "some-value").getOrCreate()import spark.implicits._val df = spark.read.json("examples/src/main/resources/employee.json")df.show() |
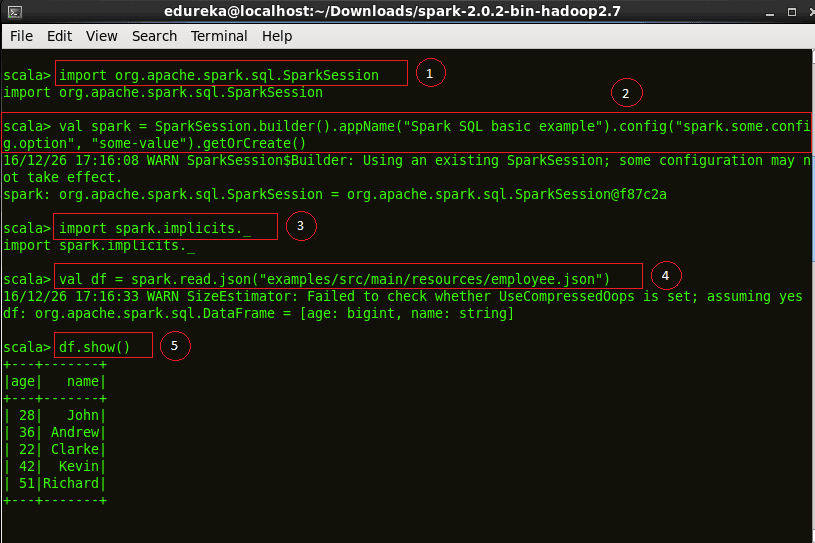 Figure:Starting a Spark Session and displaying DataFrame of employee.json
Figure:Starting a Spark Session and displaying DataFrame of employee.json
Code explanation:
1. Importing the Implicts class into our ‘spark’ Session.
2. Printing the schema of our ‘df’ DataFrame.
3. Displaying the names of all our records from ‘df’ DataFrame.
|
1
2
3
|
import spark.implicits._df.printSchema()df.select("name").show() |
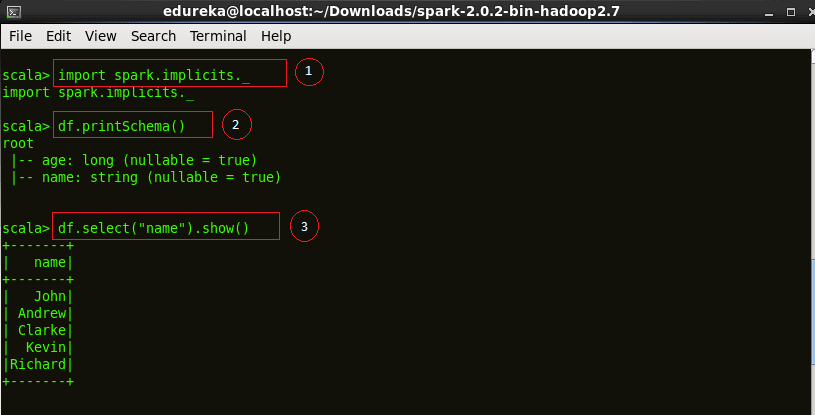 Figure:Schema of a DataFrame
Figure:Schema of a DataFrame
Code explanation:
1. Displaying the DataFrame after incrementing everyone’s age by two years.
2. We filter all the employees above age 30 and display the result.
|
1
2
|
df.select($"name", $"age" + 2).show()df.filter($"age" > 30).show() |
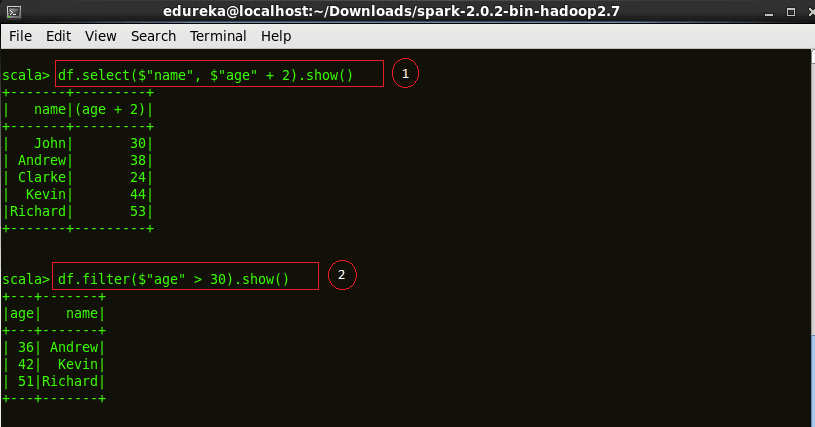 Figure:Basic SQL operations on employee.json
Figure:Basic SQL operations on employee.json
Code explanation:
1. Counting the number of people with the same ages. We use the ‘groupBy’ function for the same.
2. Creating a temporary view ’employee’ of our ‘df’ DataFrame.
3. Perform a ‘select’ operation on our ’employee’ view to display the table into ‘sqlDF’.
4. Displaying the results of ‘sqlDF’.
|
1
2
3
4
|
df.groupBy("age").count().show()df.createOrReplaceTempView("employee")val sqlDF = spark.sql("SELECT * FROM employee")sqlDF.show() |
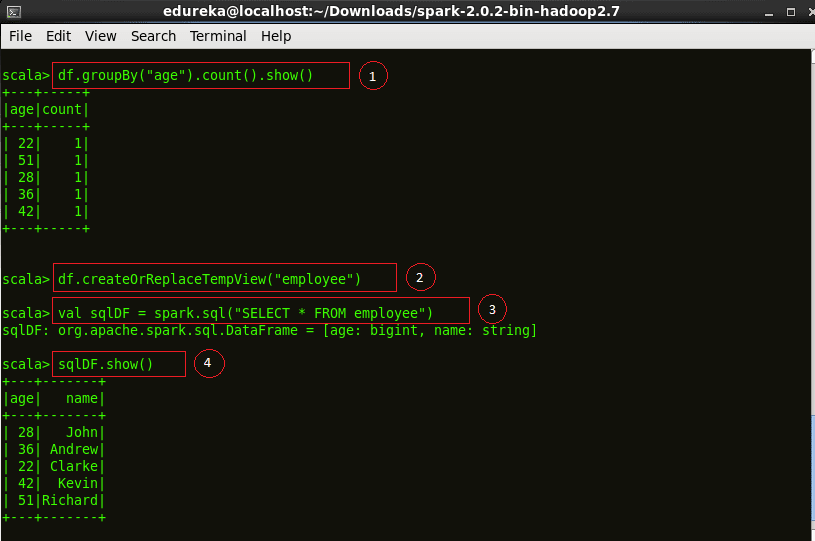 Figure:SQL operations on employee.json
Figure:SQL operations on employee.json
Source: Spark SQL Tutorial | Understanding Spark SQL With Examples | Edureka

Transforming Enterprises with
Data & AI Services & Solutions.
ThirdEye delivers Data and AI services & solutions for enterprises worldwide by
leveraging state-of-the-art Data & AI technologies.

