Customers
Projects
Industries
Technologies
Microsoft
Developing end-to-end Solutions, Custom Applications, POCs, and Demos using the latest Big Data, Artificial Intelligence, Cognitive Services & Machine Learning technologies.
- Azure OpenAI Chatbot for Enterprise Data using RAG, Semantic Kernel, and LangChain
- Social Media Campaign Generation – using AOAI, Dall-E 2,Florence
- Contact Center Analytics – Recommendation, Summarization, Voice Synthesis (using CNV)
- Vector Search & AI Assistant with AOAI, Azure Cosmos DB and Azure Cognitive Search
- Microsoft Fabric with LLM Prompt Flow in Azure ML
- Worked on 35+ end-to-end Power BI projects,
developing 300+ dashboards & reports. - Hands on experience in Power BI Desktop, Power
BI Service, Embedded Power BI. - Hands on experience on Power BI Rest APIs.
- Handle Power BI datasets from .NET applications.
- Understanding of all advanced features of Power BI Desktop that helps BI professionals manage datasets and perform operations on data fields.
- Access data from Microsoft data sources in Power BI like SQL DB, SQL DW, Azure Data Lake, Azure Storage Account etc.
- Access data from non Microsoft technologies like Salesforce, Hadoop clusters, Apache Spark clusters etc.
After the user logs in, the default landing page is the PowerBI dashboard which shows:
- History Analysis,
- Real-time Analysis and
- Predictive Analysis of the Donor and Surgical Evaluations.
The Power BI dashboards shows insights from various data sources including SharePoint, Azure Analysis Services, and real-time tweets data.
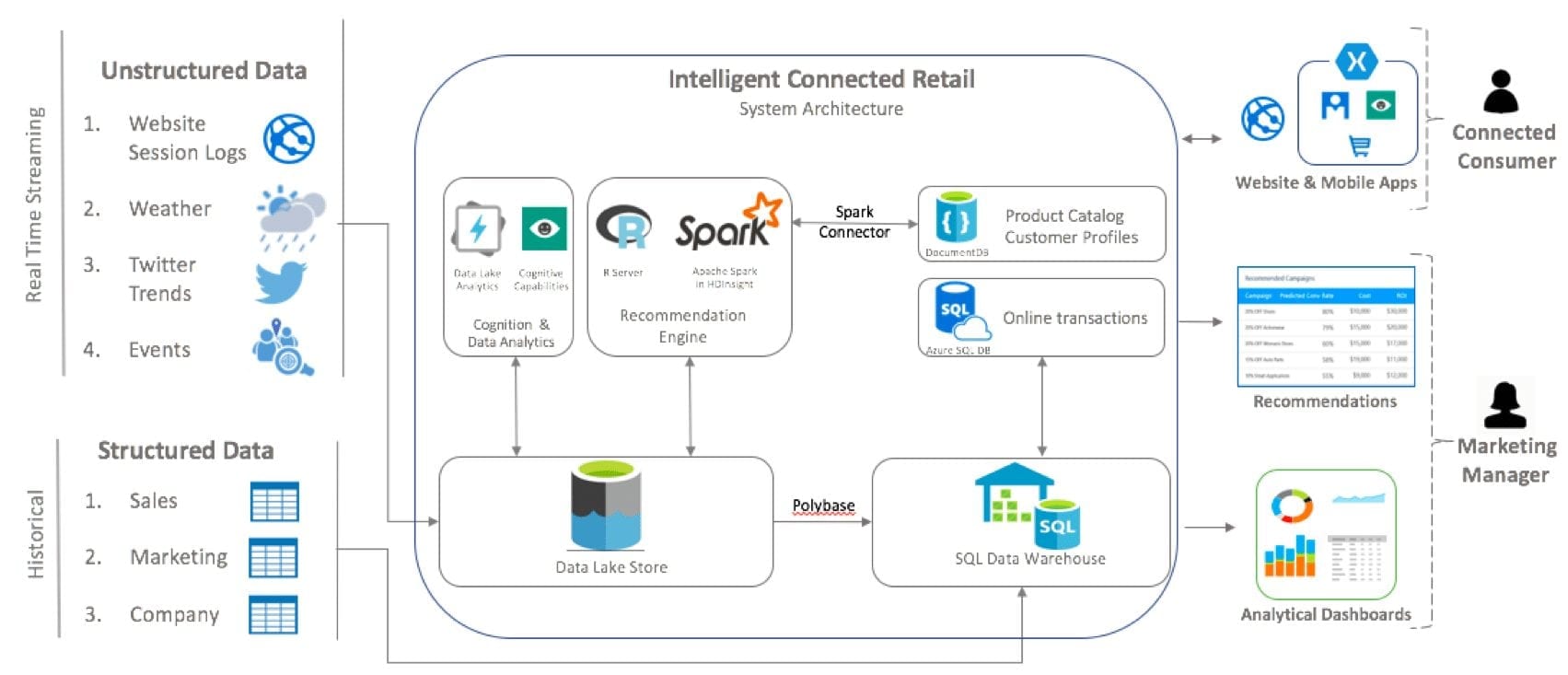
- Developed an end-to-end analytical & predictive solution that enhances Customer Experience using Omni-Channel presence with Microsoft Azure.
- The solution connects the in-store and online experiences of the customers and highlights the difference between a Connected Consumer and a Traditional Shopper.
- Provides dynamic recommendations and a 360-degree cyclic data exchange.
Zero-touch purchasing experiences with reliable and secure transaction authorization using Face Recognition.
Connected Retail Architecture
Technologies Used
![]()
- Developed an analytical & predictive solution that leverages internal, external and open data to help in their mission of helping young people transform their lives.
- Advanced machine learning principles were applied to predict drop-out rates and develop best case scenarios for helping convicted individuals start contributing to society.
Technologies Used: Windows Azure, Azure EventHub, HDInsights, Azure Data Factory, Azure Storage, PowerBI, HDFS.
- Developed a PowerApp based interactive application that helps non-technical personnel manage & scale a modern data warehouse quickly & cost-effectively.
- With a click of a button in a PowerApp:
- Create & Load a Data Warehouse with static data.
- Ingest Real-Time data.
- Scale the Data Warehouse to meet changing data needs.
- Display estimated costs for the new setup.
Technologies Used: Azure SQL Data Warehouse, Azure Data Factory, Azure Web API, Azure Storage, PowerApp.
The labs were meant for Big Data professionals who work on the Azure Cloud but are new to Apache Spark.
The labs enabled them to:
- Understand the value proposition of Apache Spark over other Big Data technologies like Hadoop.
- Understand the similarities between Hadoop & Spark, their differences, and respective nuances.
- Decide when to use what technology and why for a given business use case.
Following labs were developed:
- Lab 1 – SparkSQL – Introduction, Analyze & Visualize
Seamlessly mix SQL queries with Spark programs, enable Uniform Data Access, showcase Hive Compatibility - Lab 2 – Real time analytics using Spark Streaming
Developed classical ‘Sessionization’ techniques to enable web marketers to develop highly personalized marketing campaigns for website visitors in near real time.
- Lab 3 – Building Recommendation Systems using Spark ML
- Implementation of ‘Frequently Bought Together’ use case by “Frequent Pattern Mining” algorithm.
- Implementation of ‘People Like You Also Like This’ use case by “Collaborative Filtering” algorithm.
All implementations were enabled in a fictitious web site for students to visualize the effects of each lab work.
The labs were released to the field training team.
Technologies Used: HDInsights Spark, SparkSQL, Spark Streaming, SparkML, Jupyter, Zeppelin, R, Scala, C#, SQL, HDFS, PowerBI.
- An end-to-end fully functional demo that highlights the value proposition of ‘Connected Cars’ use case for all stakeholders – car drivers, insurance companies & automobile manufacturers.
- Leverages Big Data technologies to gain real-time predictive insights on vehicle health, driving pattern behaviors, and anomaly detection, with clean visualizations on PowerBI.
The demo was released to the field sales team.
Technologies Used: Windows Azure, Azure EventHub, HDInsights, Azure Streaming Analytics, AzureML, Azure Data Factory, Azure Storage, PowerBI, Office 2015, HDFS.
- An end-to-end fully functional system to detect and analyze crime hotspots. Also has the ability to predict the probability of the type crime that can happen at any date and time.
- Open crime data for the city of Chicago, coupled with US Govt. Census data & weather, traffic, and social media data were leveraged to perform the batch, real-time and predictive analytics.
The demo was released to the field sales team.
Technologies Used: Windows Azure, Azure Queue, Windows HDInsights, StreamInsight, SQL Azure, SQL Server, PowerBI, PowerQ&A, PowerQuery, PowerPivot, PowerView, PowerMap, Office 2013, HDFS, MapReduce, Hive.
![]()

- An end-to-end fully functional system system to analyze & predict which products, either on the web site or in physical stores, are most likely to be bought.
- Integrated real-time data from Session logs & Kinect APIs with CRM & ERP systems to process & perform AzureML based predictions.
Demo was showcased at WPC 2014 held in Washington DC.
Technologies Used: Windows Azure, Azure Queue, Windows HDInsights, AzureML, SQL Azure, PowerBI, PowerQ&A, PowerQuery, PowerPivot, PowerView, PowerMap, Office 2013, HDFS, MapReduce, Hive.
- An end-to-end fully functional demo that showcases the ease of deployment of data pipelines for real-time streaming and batch data processing.
- Data is scored in real-time using AzureML, and prescriptive predictions visualized on HTML5 based web pages.
- The drill-down analysis provides full operational control and knowledge.
The demo was released to the field sales team.
Technologies Used: Windows Azure, Azure EventHub, HDInsights, Azure Storm, AzureML, Azure Data Factory, Azure Storage, Hbase, HDFS, HTML5, CSS3, Angular.js.
- A fully functional demo of Fraud Detection scenarios for Microsoft’s Cyber Crime Detection & Prevention Center .
- Investigated fraudulent product license usages by analyzing diverse data sets in an Azure cloud environment.
Demo was showcased at WPC 2014 held in Washington DC.
Technologies Used: Windows Azure, Azure Queue, Windows HDInsights, AzureML, SQL Azure, PowerBI, PowerQ&A, PowerQuery, PowerPivot, PowerView, PowerMap, Office 2013, HDFS, MapReduce, Hive.
- Developed fully functional demo for Online Retail eCommerce Sites to analyze their advertisement performance and validate return on investments.
- Detailed User Behavior analytics helped the site owners to develop targeted and better-performing ads.
- Predictive analytics foretold possible user actions and hence helped site owners to develop relevant ads.
Technologies Used: Windows Azure, Windows HDInsights, MS SQL Server, PowerPivot, PowerView, Office 2013, MapReduce, Hive, Pig, Apache Mahout
.
- Developed a fully functional demo to help government agencies to better plan traffic infrastructure.
- Crunched through historical & real-time traffic data for city planners to perform what-if scenarios of traffic conditions during selected date & time.
- Real-time configurations enabled city planners to visualize the stress of traffic on various routes and hence direct drivers to faster routes.
The demo was released to the field sales team.
Technologies Used: Windows Azure, Windows HDInsights, MS SQL Server, PHP, HTML5, CSS3, JQuery, MapReduce, Hive, Pig, HBase.
- A fully functional demo for Online Retailers to identify their best selling products, most paying customers and performance of their website.
- Delivered analytical dashboards that helped retailers to develop revenue enhancing strategies
The demo was released to the field sales team.
Technologies Used: Windows Azure, Windows HDInsights, MS SQL Server, MapReduce, Hive, Pig, Apache Mahout, PowerPivot, PowerView, Office 2013.
ThirdEye’s team was part of the technical team that was responsible for the launch of Azure Synapse.
Azure Synapse is a new product offering that offers limitless analytics service that brings together enterprise data warehousing and Big Data analytics
Showcased the following technical topics:
- Migrate to Azure Synapse Analytics
- Apache Spark, Azure ML integration in Spark notebooks
- Apache Spark, Azure ML integration in Spark notebooks
- Data Lake (data at rest) and Delta lake (lambda architecture)
- Data warehouse with trillions of rows,
workload isolation, workload importance - Code-free, Code-first data orchestration
- Streaming ingestion & near real-time analytics
- Ad-hock queries
- Enterprise security at Column level, Row level etc.
ThirdEye’s team is the technical brains behind a new YouTube channel named
Advanced Analytics with Azure plus the internal channel named Azure TV.
- Developed all technical content & code as shown in these videos.
- Topics include Data & BI with Advanced Analytics, Infrastructure, Artificial Intelligence, IoT, Azure Consumption, Architecture, DevOps, and Application Dev.
