MapReduce Tutorial: MapReduce Architecture
The figure shown below illustrates the various parameters and modules that can be configured during a MapReduce operation:
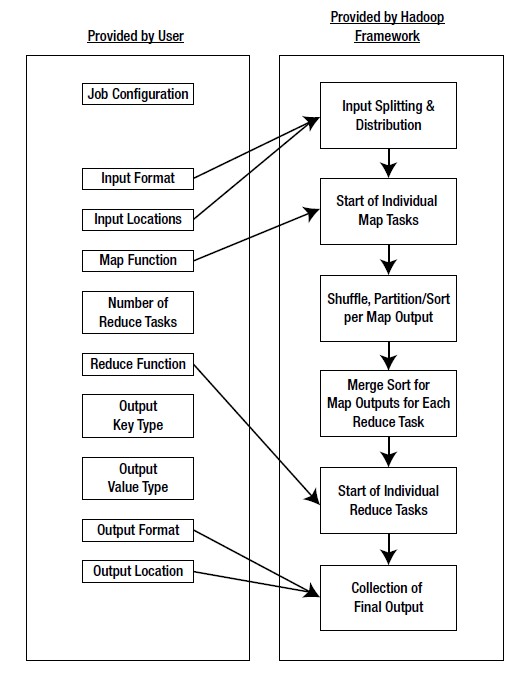
JobConf is the framework used to provide various parameters of a MapReduce job to the Hadoop for execution. The Hadoop platforms executes the programs based on configuration set using JobConf. The parameters being Map Function, Reduce Function, combiner , Partitioning function, Input and Output format. Partitioner controls the shuffling of the tuples when being sent from Mapper node to Reducer nodes. The total number of partitions done in the tuples is equal to the number of reduce nodes. In simple terms based on the function output the tuples are transmitted through different reduce nodes.
Input Format describes the format of the input data for a MapReduce job. Input location specifies the location of the datafile. Map Function/ Mapper convert the data into key value pair. For example let’s consider daily temperature data of 100 cities for the past 10 years. In this the map function is written such a way that every temperature being mapped to the corresponding city. Reduce Function reduces the set of tuples which share a key to a single tuple with a change in the value. In this example if we have to find the highest temperature recorded in the city the reducer function is written in such a way that it return the tuple with highest value i.e: highest temperature in the city in that sample data.
The number of Map and Reduce nodes can also be defined. You can set Partitioner function which partitions and transfer the tuples which by default is based on a hash function. In other words we can set the options such that a specific set of key value pairs are transferred to a specific reduce task. For example if your key value consists of the year it was recorded, then we can set the parameters such that all the keys of specific year are transferred to a same reduce task. The Hadoop framework consists of a single master and many slaves. Each master has JobTracker and each slave has TaskTracker. Master distributes the program and data to the slaves. Task tracker, as the name suggests keep track of the task directed to it and relays the information to the JobTracker. The JobTracker monitors all the status reports and re-initiates the failed tasks if any.
Combiner class are run on map task nodes. It takes the tuples emitted by Map nodes as input. It basically does reduce operation on the tuples emitted by the map node. It is like a pre- reduce task to save a lot of bandwidth. We can also pass global constants to all the nodes using ‘Counters’. They can be used to keep track of all events in map and reduce tasks. For example we can pass a counter to calculate the statistics of an event beyond a certain threshold.
MapReduce Tutorial: A Word Count Example of MapReduce
Let us understand, how a MapReduce works by taking an example where I have a text file called example.txt whose contents are as follows:
Dear, Bear, River, Car, Car, River, Deer, Car and Bear
Now, suppose, we have to perform a word count on the sample.txt using MapReduce. So, we will be finding the unique words and the number of occurrences of those unique words.
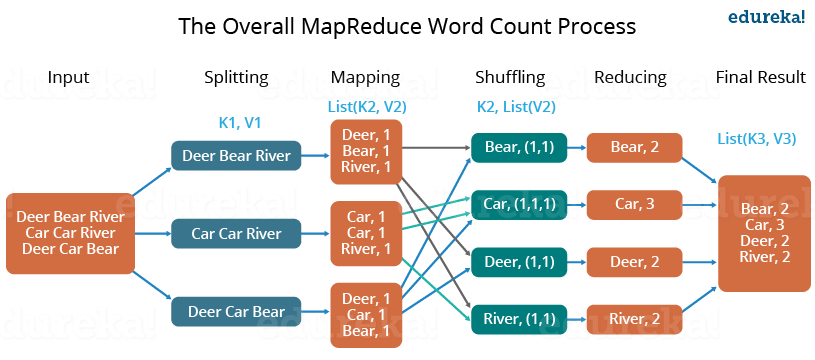
- First, we divide the input in three splits as shown in the figure. This will distribute the work among all the map nodes.
- Then, we tokenize the words in each of the mapper and give a hardcoded value (1) to each of the tokens or words. The rationale behind giving a hardcoded value equal to 1 is that every word, in itself, will occur once.
- Now, a list of key-value pair will be created where the key is nothing but the individual words and value is one. So, for the first line (Dear Bear River) we have 3 key-value pairs – Dear, 1; Bear, 1; River, 1. The mapping process remains the same on all the nodes.
- After mapper phase, a partition process takes place where sorting and shuffling happens so that all the tuples with the same key are sent to the corresponding reducer.
- So, after the sorting and shuffling phase, each reducer will have a unique key and a list of values corresponding to that very key. For example, Bear, [1,1]; Car, [1,1,1].., etc.
- Now, each Reducer counts the values which are present in that list of values. As shown in the figure, reducer gets a list of values which is [1,1] for the key Bear. Then, it counts the number of ones in the very list and gives the final output as – Bear, 2.
- Finally, all the output key/value pairs are then collected and written in the output file.
MapReduce Tutorial: Advantages of MapReduce
The two biggest advantages of MapReduce are:
1. Parallel Processing:
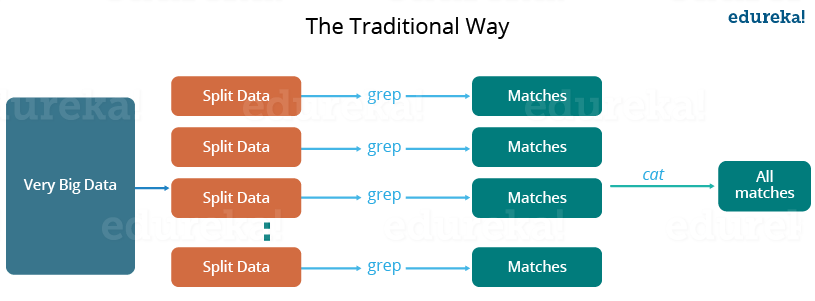
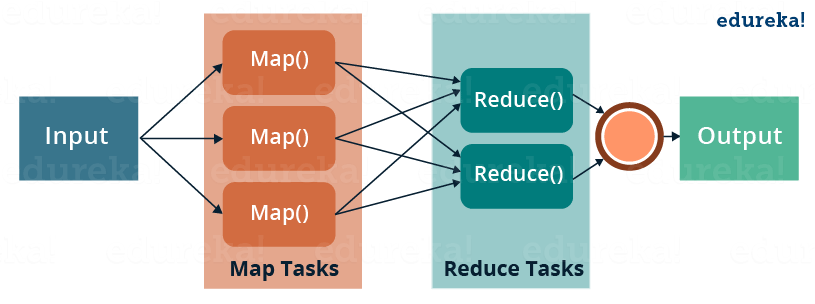
In MapReduce, we are dividing the job among multiple nodes and each node works with a part of the job simultaneously. So, MapReduce is based on Divide and Conquer paradigm which helps us to process the data using different machines. As the data is processed by multiple machine instead of a single machine in parallel, the time taken to process the data gets reduced by a tremendous amount as shown in the figure below (2).
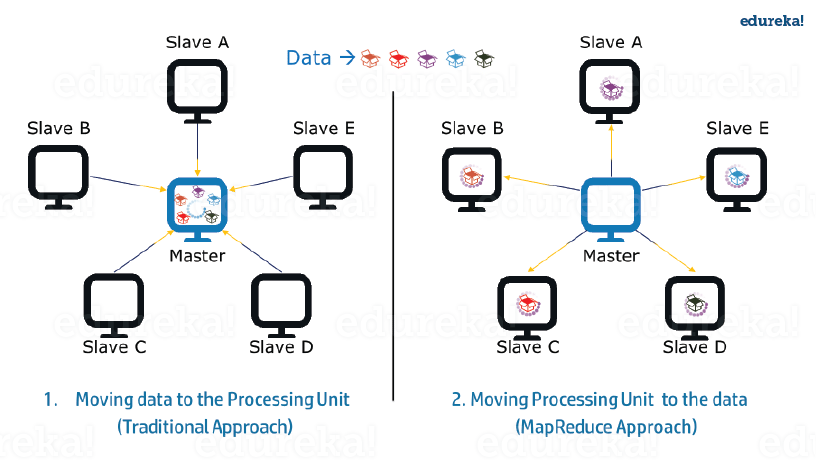 Fig.: Traditional Way Vs. MapReduce Way – MapReduce Tutorial
Fig.: Traditional Way Vs. MapReduce Way – MapReduce Tutorial
2. Data Locality:
Instead of moving data to the processing unit, we are moving processing unit to the data in the MapReduce Framework. In the traditional system, we used to bring data to the processing unit and process it. But, as the data grew and became very huge, bringing this huge amount of data to the processing unit posed following issues:
- Moving huge data to processing is costly and deteriorates the network performance.
- Processing takes time as the data is processed by a single unit which becomes the bottleneck.
- Master node can get over-burdened and may fail.
Now, MapReduce allows us to overcome above issues by bringing the processing unit to the data. So, as you can see in the above image that the data is distributed among multiple nodes where each node processes the part of the data residing on it. This allows us to have the following advantages:
- It is very cost effective to move processing unit to the data.
- The processing time is reduced as all the nodes are working with their part of the data in parallel.
- Every node gets a part of the data to process and therefore, there is no chance of a node getting overburdened.
MapReduce Tutorial: MapReduce Example Program
Before jumping into the details, let us have a glance at a MapReduce example program to have a basic idea about how things work in a MapReduce environment practically. I have taken the same word count example where I have to find out the number of occurrences of each word. And Don’t worry guys, if you don’t understand the code when you look at it for the first time, just bear with me while I walk you through each part of the MapReduce code.
Source code:
package co.edureka.mapreduce;import java.io.IOException;import java.util.StringTokenizer;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.fs.Path;public class WordCount{public static class Map extends Mapper<LongWritable,Text,Text,IntWritable> {public void map(LongWritable key, Text value,Context context) throws IOException,InterruptedException{String line = value.toString();StringTokenizer tokenizer = new StringTokenizer(line);while (tokenizer.hasMoreTokens()) {value.set(tokenizer.nextToken());context.write(value, new IntWritable(1));}}}public static class Reduce extends Reducer<Text,IntWritable,Text,IntWritable> {public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException,InterruptedException {int sum=0;for(IntWritable x: values){sum+=x.get();}context.write(key, new IntWritable(sum));}}public static void main(String[] args) throws Exception {Configuration conf= new Configuration();Job job = new Job(conf,"My Word Count Program");job.setJarByClass(WordCount.class);job.setMapperClass(Map.class);job.setReducerClass(Reduce.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);job.setInputFormatClass(TextInputFormat.class);job.setOutputFormatClass(TextOutputFormat.class);Path outputPath = new Path(args[1]);//Configuring the input/output path from the filesystem into the jobFileInputFormat.addInputPath(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));//deleting the output path automatically from hdfs so that we don't have to delete it explicitlyoutputPath.getFileSystem(conf).delete(outputPath);//exiting the job only if the flag value becomes falseSystem.exit(job.waitForCompletion(true) ? 0 : 1);}} |
MapReduce Tutorial: Explanation of MapReduce Program
- Mapper Phase Code
- Reducer Phase Code
- Driver Code
Mapper code:
public static class Map extends Mapper<LongWritable,Text,Text,IntWritable> {public void map(LongWritable key, Text value, Context context) throws IOException,InterruptedException {String line = value.toString();StringTokenizer tokenizer = new StringTokenizer(line);while (tokenizer.hasMoreTokens()) {value.set(tokenizer.nextToken());context.write(value, new IntWritable(1));} |
- We have created a class Map that extends the class Mapper which is already defined in the MapReduce Framework.

- We define the data types of input and output key/value pair after the class declaration using angle brackets.
- Both the input and output of the Mapper is a key/value pair.
- Input:
- The key is nothing but the offset of each line in the text file:LongWritable
- The value is each individual line (as shown in the figure at the right): Text
- Output:
- The key is the tokenized words: Text
- We have the hardcoded value in our case which is 1: IntWritable
- Example – Dear 1, Bear 1, etc.
- We have written a java code where we have tokenized each word and assigned them a hardcoded value equal to 1.
Reducer Code:
public static class Reduce extends Reducer<Text,IntWritable,Text,IntWritable> {public void reduce(Text key, Iterable<IntWritable> values,Context context)throws IOException,InterruptedException {int sum=0;for(IntWritable x: values){sum+=x.get();}context.write(key, new IntWritable(sum));}} |
- We have created a class Reduce which extends class Reducer like that of Mapper.
- We define the data types of input and output key/value pair after the class declaration using angle brackets as done for Mapper.
- Both the input and the output of the Reducer is a key-value pair.
- Input:
- The key nothing but those unique words which have been generated after the sorting and shuffling phase: Text
- The value is a list of integers corresponding to each key: IntWritable
- Example – Bear, [1, 1], etc.
- Output:
- The key is all the unique words present in the input text file: Text
- The value is the number of occurrences of each of the unique words: IntWritable
- Example – Bear, 2; Car, 3, etc.
- We have aggregated the values present in each of the list corresponding to each key and produced the final answer.
- In general, a single reducer is created for each of the unique words, but, you can specify the number of reducer in mapred-site.xml.
Driver Code:
Configuration conf= new Configuration();Job job = new Job(conf,"My Word Count Program");job.setJarByClass(WordCount.class);job.setMapperClass(Map.class);job.setReducerClass(Reduce.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);job.setInputFormatClass(TextInputFormat.class);job.setOutputFormatClass(TextOutputFormat.class);Path outputPath = new Path(args[1]);//Configuring the input/output path from the filesystem into the jobFileInputFormat.addInputPath(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1])); |
- In the driver class, we set the configuration of our MapReduce job to run in Hadoop.
- We specify the name of the job , the data type of input/output of the mapper and reducer.
- We also specify the names of the mapper and reducer classes.
- The path of the input and output folder is also specified.
- The method setInputFormatClass () is used for specifying that how a Mapper will read the input data or what will be the unit of work. Here, we have chosen TextInputFormat so that single line is read by the mapper at a time from the input text file.
- The main () method is the entry point for the driver. In this method, we instantiate a new Configuration object for the job.
Run the MapReduce code:
The command for running a MapReduce code is:
hadoop jar hadoop-mapreduce-example.jar WordCount /sample/input /sample/output
Now, you guys have a basic understanding of MapReduce framework. You would have realized how the MapReduce framework facilitates us to write code to process huge data present in the HDFS. There has been significant changes in the MapReduce framework in Hadoop 2.x as compared to Hadoop 1.x. These changes will be discussed in the next blog of this MapReduce tutorial series. I will share a downloadable comprehensive guide which explains each part of the MapReduce program in that very blog.


