
fbProphet – Comparative Analysis of Incremental and Normal Learning
This blog presents a comprehensive analysis of ‘incremental learning’ with fbProphet with different approaches. Analysis was done on data provided by one of ThirdEye’s clients. Five metrics with different patterns were picked from the data for our analysis. The main purpose of this report is to showcase how incremental learning behaves for fbProphet and how it can be beneficial in the long run.
Incremental Learning (or partial fitting): In computer science, incremental learning is a method of machine learning in which input data is continuously used to extend the existing model’s knowledge i.e. to further train the model.
Comparative Analysis Approaches
For the purpose of comparison, we picked 5 different metrics and trained the fbProphet model on
- Whole data at once
- Initial training on 30 days of data and retraining on data of 31st data
- Initial training on day 1 and retraining on 1 day at a time, thus retraining 30 times after initial training.
Approach 1 – Training on up to 30th day and partial fit on 31st day
In this approach, we trained our model on data up to 30th day and that model was again retrained on 31st day i.e. the parameters were updated. In this approach, we are trying to showcase the scenario, where the initial model is trained on a larger chunk of data (like 1 year worth of data) and retraining will be done on smaller chunks as time goes by.
Approach 2 – Training on 31 chunks of data for 31 days of data available in the dataset
In this approach, we divided the data into chunks. As the data that we had was for 1 month i.e 31 days. So the chunks were done on the basis of days. So we had 31 chunks of data. Each data represents a day as mentioned. Now if the array of the data is d1,d2,…,d31.
Then the model was first trained on d1 and the parameters were stored in a binary file. Then when d2 is passed, the parameters of the model which was trained on d1 were updated (i.e here we are reusing the model trained on the previous day (dk-1) when we are training it for dk ).
Analysis Results
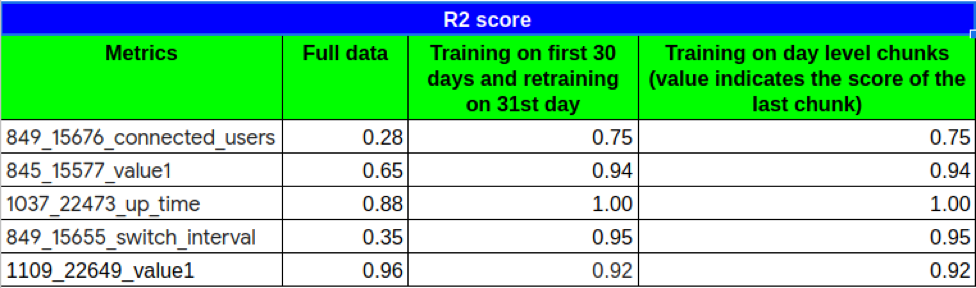
As we can see that model performs better with partial fitting (R2 score is a metric to evaluate model, r2 score close to 1 indicates good model). We also see that approach 1 and approach 2 perform similarily, which indicates that with more retraining, the model converges to the optimum result.
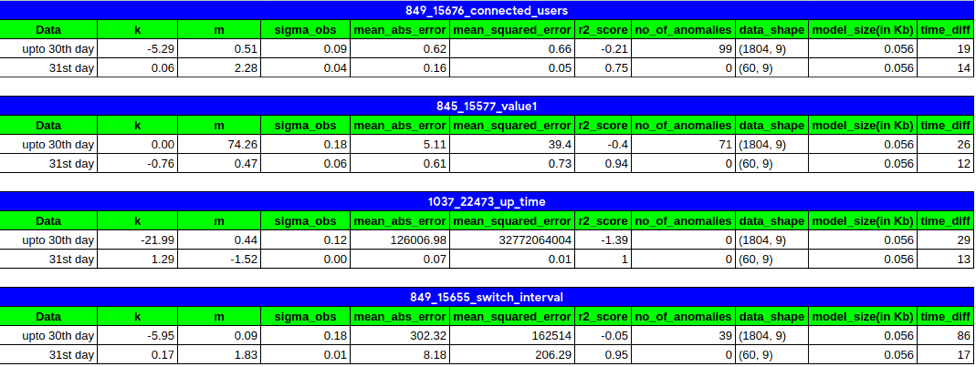
Here we can see that from the initial model, the r2 score improves when retrained. Also, we can see that for all the 5 metrics, time is taken (sec) is higher than when retrained on only 1 day worth of data (31st day).
Conclusion
We conclude that incremental learning works for fbProphet model, and actually improves the performance. This report also indicates that initially we can train our model on the larger dataset (like 1 year worth of data) and keep on retraining the model on the incremental learning basis to update the model on a newer, smaller dataset which requires less resource than initial training and takes less time to complete the model updatation.





