Overview
One of the ways to integrate with external systems is using the Extract, Transform, Load (ETL) system. The ETL system creates databases which can be accessed directly by 3rd party tools and solutions. It also allows scheduled execution of transformation scripts on the Data Center Operation server. Together this gives the ability to extract and enter data on the Data Center Operation server.
Based on the ETL system, it is possible to develop custom solutions, integrating DCO with a broad range of data sources.
ETL can be used in 2 ways: Importing Data in to and Exporting Data from Data Center Operation
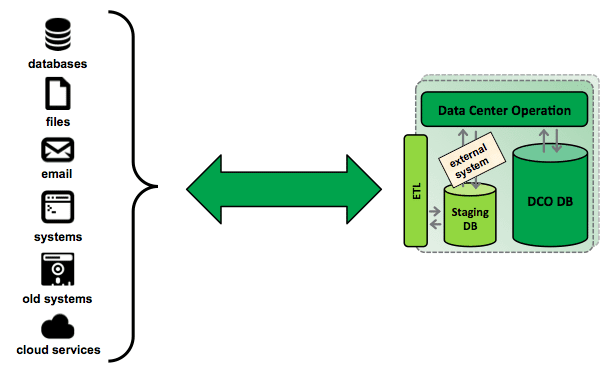
External system integration using ETL
ETL modeling concepts
The general framework for ETL processes is shown in Fig. 1. Data is extracted from different data sources and then propagated to the DSA where it is transformed and cleansed before being loaded into the data warehouse. Source, staging area, and target environments may have many different data structure formats as flat files, XML data sets, relational tables, non-relational sources, weblog sources, legacy systems, and spreadsheets.

Figure 1. A general framework for ETL processes.
ETL phases
An ETL system consists of three consecutive functional steps: extraction, transformation, and loading:
1.Extraction
The first step in any ETL scenario is data extraction. The ETL extraction step is responsible for extracting data from the source systems. Each data source has its distinct set of characteristics that need to be managed in order to effectively extract data for the ETL process. The process needs to effectively integrate systems that have different platforms, such as different database management systems, different operating systems, and different communications protocols.
During extracting data from different data sources, the ETL team should be aware of (a) using ODBC⧹JDBC drivers connect to database sources, (b) understanding the data structure of sources, and (c) know how to handle the sources with different nature such as mainframes. The extraction process consists of two phases, initial extraction and changed data extraction. In the initial extraction (Kimball et al., 1998), it is the first time to get the data from the different operational sources to be loaded into the data warehouse. This process is done only one time after building the DW to populate it with a huge amount of data from source systems. The incremental extraction is called changed data capture (CDC) where the ETL processes refresh the DW with the modified and added data in the source systems since the last extraction. This process is periodic according to the refresh cycle and business needs. It also captures only changed data since the last extraction by using many techniques as audit columns, database log, system date, or delta technique.
2.Transformation
The second step in any ETL scenario is data transformation. The transformation step tends to make some cleaning and conforming on the incoming data to gain accurate data which is correct, complete, consistent, and unambiguous. This process includes data cleaning, transformation, and integration. It defines the granularity of fact tables, the dimension tables, DW schema (stare or snowflake), derived facts, slowly changing dimensions, factless fact tables. All transformation rules and the resulting schemas are described in the metadata repository.
3.Loading
Loading data to the target multidimensional structure is the final ETL step. In this step, extracted and transformed data is written into the dimensional structures actually accessed by the end users and application systems. Loading step includes both loading dimension tables and loading fact tables.
Importing Data
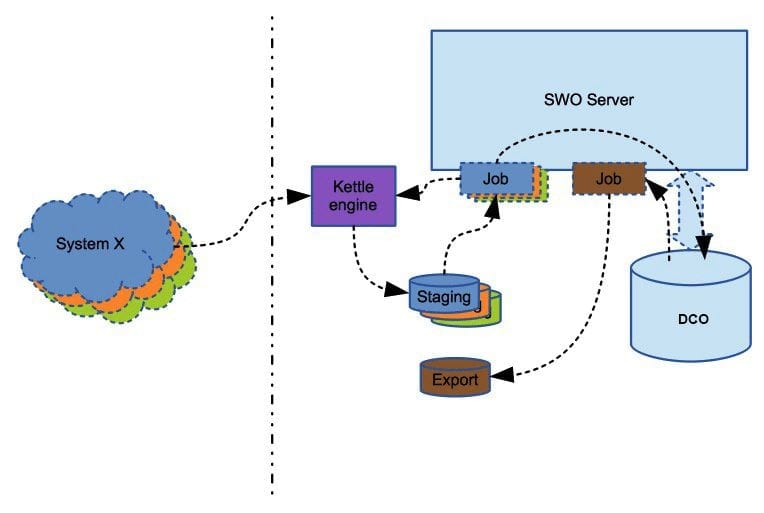
- Importing data into Data Center Operation is used whenever data must be provided to DCO.
The data is being imported via the ETL Import Database.
There are 2 ways of importing data. One where “Data is Ready” and one where “Data needs change” before being used in DCO.- Data is Ready
When data is ready the only thing that must be done is set up the integration between the external system providing data andDCO.
This is done at the database level. The integration is configured using the server configuration interface - Data needs change
When data needs to be changed/modified before it is used inside DCO this can be done using a transformation or a set of transformations called a job.
Once transformation(s) are in place the integration is configured using the server configuration interface
- Data is Ready
- Finally, once the database integration(s) are in place the external system can be configured to get data into DCO from the external system via the ETL import database.
Exporting Data
- Exporting data from Data Center Operation is used whenever data is used outside DCO.
The data is exported using the ETL Export Database.
The data exported from Data Center Operation cannot be changed by transformations inside the Data Center Operation server. If the transformation is needed this must be done outside the server in a separate setup. - Setting up the database integration is done using the server configuration interface
- Once the database integration(s) are in place the external system can be configured to push data from DCO to the ETL export database from where the data can then be fetched.
Import and Export Database in External System Integration using ETL
Upgrading ETL External System Integration
No files (or databases) will be deleted when upgrading/restoring a DCO system. Upgrade of the ETL system is a part of the general DCO upgrade.
When upgrading an existing solution running ETL for importing and/or exporting data to DCO a couple of guidelines are:
- Both import and export databases are viewed as “API-like” interface to the system.
- At any point in time, the data in the import and/or export database represents the currently best-known state of the system.
- The ETL databases do not contain the sole instance of any piece of data.
Database
This means that it is always safe to drop any ETL database and recreate it without the risk of losing data.
Since no data is stored in the ETL database, it is highly recommended to drop the databases and recreate them rather than moving them. This will allow databases to follow potential new database schema(s). To use the old databases, these must be moved manually which is not recommended.
Transformations
When upgrading from previous versions the old transformation files will be moved into the folder “/data/pentaho_backup". The transformation files must manually be moved from “/data/pentaho_backup" into a potential new folder structure (described below). Restoring an old backup will place transformation files in the same structure as they were in the backed up system. Please note this might not be the correct folder structure since the structure has changed between versions.
Note: When moving/copying files into the new folder structure make sure to preserve the ownership of the folders in order for the future script to be added and executed.
The transformation files must be placed in their respective folders on the DCO server.
The transformation files folder structure on the DCO server is “/data/pentaho/export" or “/data/pentaho/import".
ETL Database Configuration
With the introduction of StruxureWare Data Center Operation, 7.4 configurations and management of ETL databases is done using the server configuration interface.
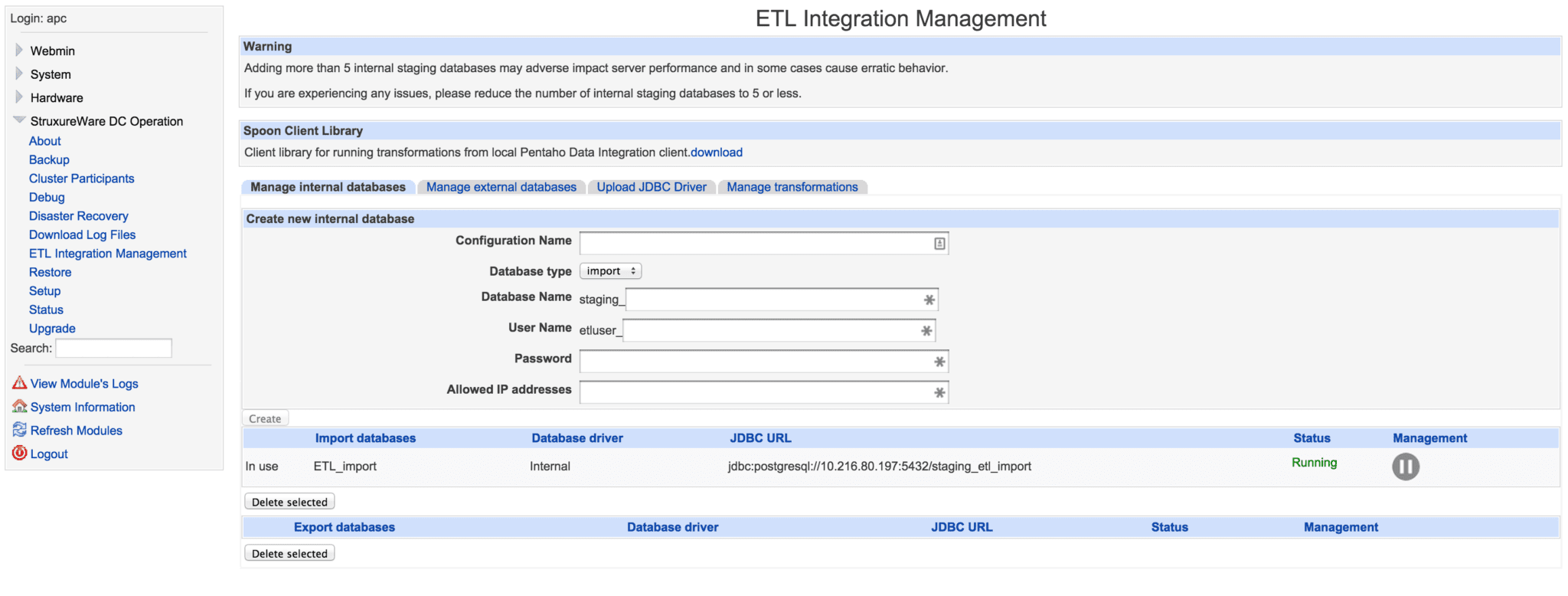
Internal Database
An Internal Database is a PostgreSQL instance running on the same server as StruxureWare Data Center Operation.
The database is created and deleted by StruxureWare Data Center Operation.
To create an internal database, you must provide the following:
- Configuration Name – the name that will later be shown in the StruxureWare Data Center Operation Client to distinguish between different databases, when configuring External Systems.
- Database Type – databases are used for either Import or export of data
- Database Name – the unique name used when creating the database. Import databases are always prefixed with ‘staging_’ and Export databases with ‘export_’
- Username – unique username. The username is prefixed by ‘etluser_’
- Password – password of the user. No special requirements.
- Allowed IP addresses – When integrating with external systems, it may be necessary to allow direct database access to the database. It is mandatory to enter the specific IP or range of IP addresses allowed to access the database.
Note: Double-byte characters are not supported in the configuration of the database
Once saved, the database is created and will subsequently be available inside the StruxureWare Data Center Operation Client.
The internal database connection can be paused/started using the pause/start management button. This can be used in order to pause/start the scheduled communication with the database. Pressing start will not force the communication to run but enable the scheduled communication to run according to schedule.
Internal Database configuration
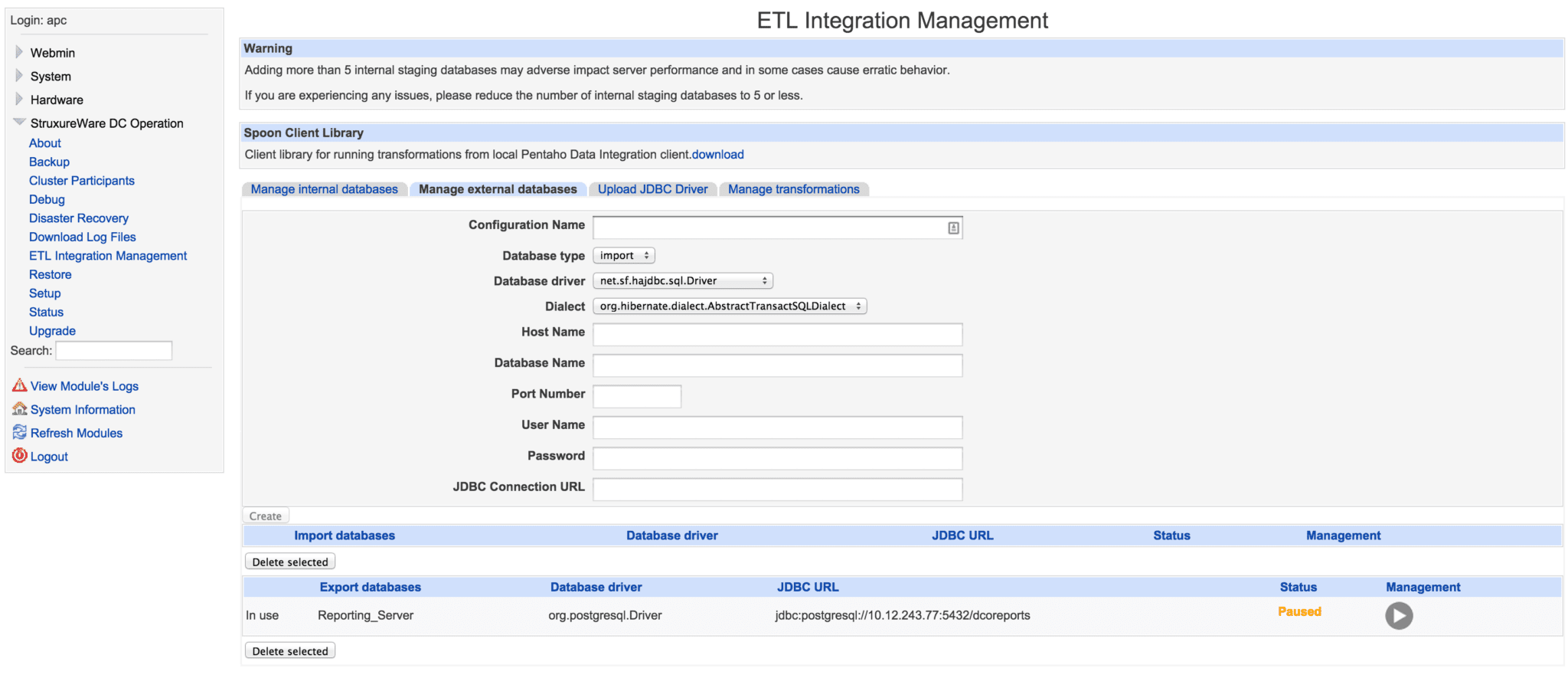
External Database
An External Database is located outside of the StruxureWare Data Center Operation server. We have tested with PostgreSQL, MS Sequel Server, and MySql database types and generally the only requirement is the existence of a JDBC4 compliant database driver. The database must be created, deleted and managed outside of StruxureWare Data Center Operation. The database must be set up using a UTF8 character encoding.
Webmin is used to create a configuration defining how to access the external database, and must include the following:
- Configuration Name – the name that will later be shown in the StruxureWare Data Center Operation Client to distinguish between different databases, when configuring External Systems.
- Database Type – databases are used for either Import or export of data
- Database Driver – choose what JDBC driver to use when connecting to the database. If the required driver does not appear in the list, it can be uploaded using the Upload database driver functionality
- Database Dialect – some databases speak several different dialects, choose the one the matches your setup.
- Database Name – the name used when connecting to the database. External databases are never prefixed.
- Port Number – specify what port is used to communicate with the external database. Please note that it may be necessary to open ports in firewalls between the StruxureWare Data Center Operation server, and the server hosting the remote database.
- Username – unique username. The username is prefixed by ‘etluser_’
- Password – password of the user. No special requirements.
- Database URL – entered values from the previous fields are combined into a database URL, if extra parameters are needed, they may be inserted into the URL.
Note: Double-byte characters are not supported in the configuration of the database
Once saved, the configuration is created and will subsequently be available as an external database inside the StruxureWare Data Center Operation Client.
The internal database connection can be paused/started using the pause/start management button. This can be used in order to pause/start the scheduled communication with the database. Pressing start will not force the communication to run but enable the scheduled communication to run according to schedule.
External Database configuration
Database Driver Upload
When using external databases of other types than PostgreSQL, it may be necessary to upload a JDBC driver to the StruxureWare Data Center Operation server. (Note: The JDBC driver must be Java 6 compatible)
This is done from the server configuration interface StruxureWare DC Operation->ETL Integration Management in the tab Upload JDBC Driver.
The required JDBC driver should be downloaded from the database vendors support site (or other trusted support site), and stored locally on the client computer.
After the upload completes, the StruxureWare Data Center Operation server must be restarted.
The ETL Integration is partly done at the database level and partly done using the StruxureWare Data Center Operation external system configuration interface.
The external system configuration for ETL integration is done by adding an external system from the System Setup-> External System Configuration menu.
Add the StruxureWare Data Center Operation ETL Integration system type.
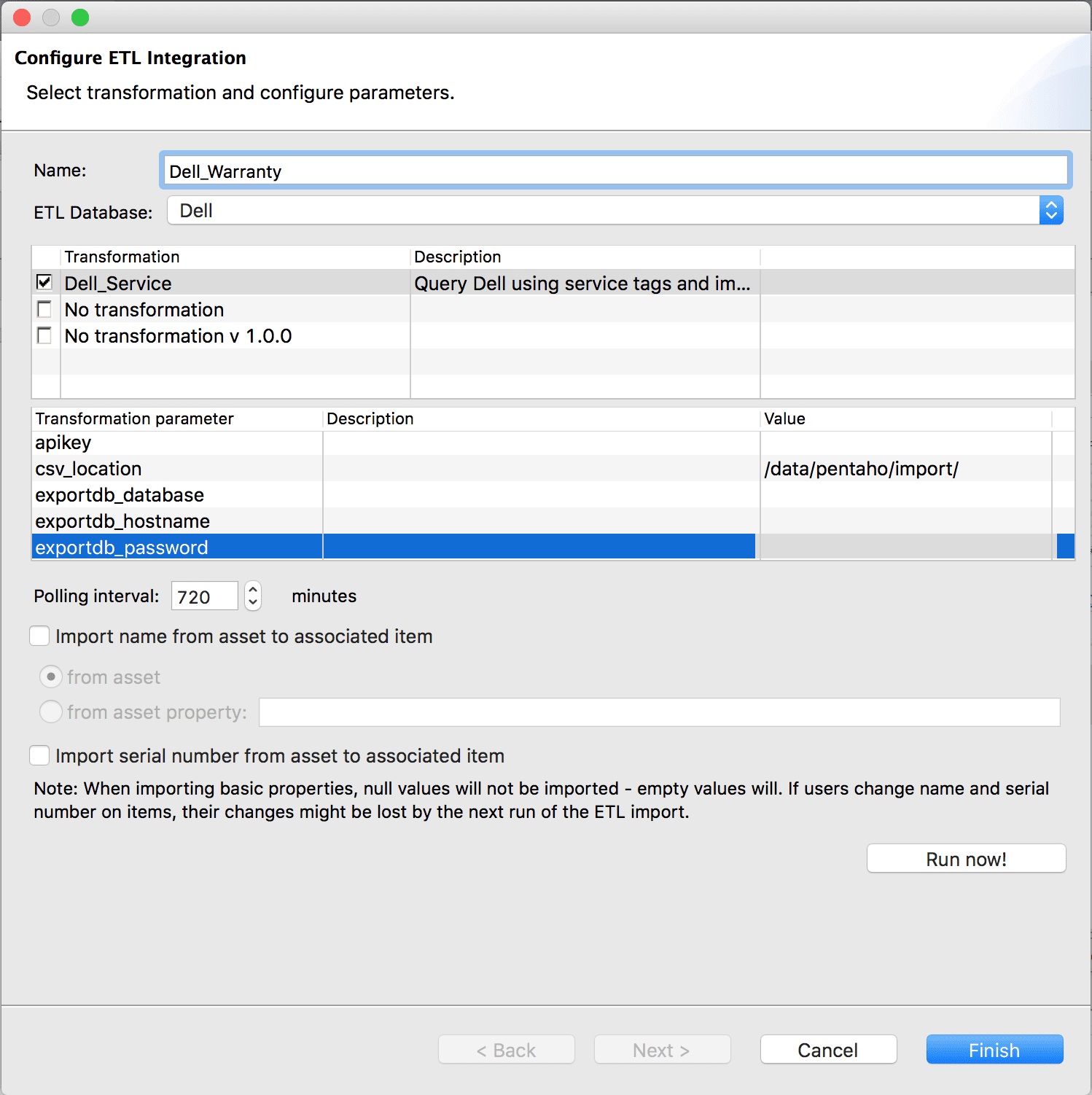
Specify the ETL Integration External System by giving it a Name and choose which ETL database to use. Both import and export are configured using the same configuration interface.
The Transformation table will be populated with the upload transformation(s). Choose the wanted transformation and the related Transformation Parameter(s) to be used for the ETL integration.
If working on an import database the CI Polling Interval specifies how often the transformation(s) is run and the database is updated.
With ETL import databases it is also possible to specify whether the name or serial number should be imported from ETL asset to the associated item in DCO. You can import the name in 2 ways:
- From the name of ETL asset. The value is imported from the column ci_name in the configuration_item table.
- From the asset property of the ETL asset. You must specify the name of the property, which is imported from the cip_namecolumn in the configration_item_property table. Only properties of type 4 are imported (meaning the row must have pt_id = 4 = ‘ASSET PROPERTY’).
Serial numbers are imported from the column ci_serial_number in the table configuration_item.
Run now! will run the transformation and update the database accordingly.
If an export database is being configured the Next button will be enabled and clicking next will give the option to schedule how often data export should be done.
ETL Integration Management – External System Configuration – Import
ETL Integration Management – External System Configuration – Export
Source: ETL – Extract Transform Load – DCIM Developer Documentation – StruxureWare for Data Centers Support
Source: A proposed model for data warehouse ETL processes – ScienceDirect
Transforming Enterprises with
Data & AI Services & Solutions.
ThirdEye delivers Data and AI services & solutions for enterprises worldwide by
leveraging state-of-the-art Data & AI technologies.


