Azure Event Hubs is a highly scalable data streaming platform and event ingestion service, capable of receiving and processing millions of events per second. Event Hubs can process and store events, data, or telemetry produced by distributed software and devices. Data sent to an event hub can be transformed and stored using any real-time analytics provider or batching/storage adapters. With the ability to provide publish-subscribe capabilities with low latency and at massive scale, Event Hubs serves as the “on-ramp” for Big Data.
Event Hubs event and telemetry handling capabilities make it especially useful for:
For example, Event Hubs enables behavior tracking in mobile apps, traffic information from web farms, in-game event capture in console games, or telemetry collected from industrial machines, connected vehicles, or other devices.
The common role that Event Hubs plays in solution architectures is the “front door” for an event pipeline, often called an event ingestor. An event ingestor is a component or service that sits between event publishers and event consumers to decouple the production of an event stream from the consumption of those events. The following figure depicts this architecture:
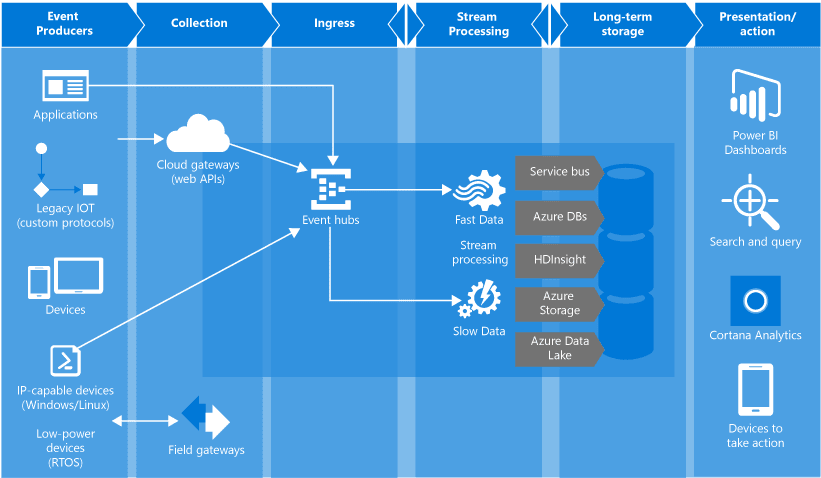
Event Hubs provides message stream handling capability but has characteristics that are different from traditional enterprise messaging. Event Hubs capabilities are built around high throughput and event processing scenarios. As such, Event Hubs is different from Azure Service Bus messaging and does not implement some of the capabilities that are available for Service Bus messaging entities, such as topics.1
Event Hubs features the following key elements:
For technical details about these and other Event Hubs features, see the Event Hubs features overview.
Any entity that sends data to an event hub is an event producer or event publisher. Event publishers can publish events using HTTPS or AMQP 1.0. Event publishers use a Shared Access Signature (SAS) token to identify themselves to an event hub and can have a unique identity, or use a common SAS token.
You can publish an event via AMQP 1.0 or HTTPS. Event Hubs provides client libraries and classes for publishing events to an event hub from .NET clients. For other runtimes and platforms, you can use any AMQP 1.0 client, such as Apache Qpid. You can publish events individually or batch. A single publication (event data instance) has a limit of 256 KB, regardless of whether it is a single event or a batch. Publishing events larger than this threshold results in an error. It is a best practice for publishers to be unaware of partitions within the event hub and to only specify a partition key (introduced in the next section), or their identity via their SAS token.
The choice to use AMQP or HTTPS is specific to the usage scenario. AMQP requires the establishment of a persistent bidirectional socket in addition to transport level security (TLS) or SSL/TLS. AMQP has higher network costs when initializing the session, however, HTTPS requires additional SSL overhead for every request. AMQP has higher performance for frequent publishers.
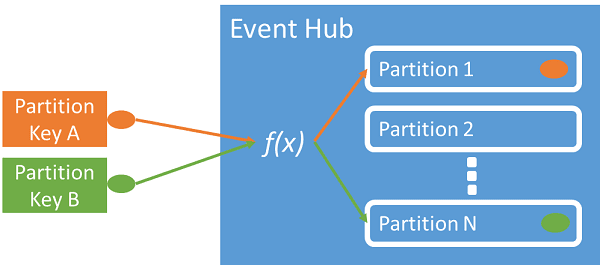
Event Hubs ensures that all events sharing a partition key value are delivered in order, and to the same partition. If partition keys are used with publisher policies, then the identity of the publisher and the value of the partition key must match. Otherwise, an error occurs.
Event Hubs enables granular control over event publishers through publisher policies. Publisher policies are run-time features designed to facilitate large numbers of independent event publishers. With publisher policies, each publisher uses its own unique identifier when publishing events to an event hub, using the following mechanism:
//[my namespace].servicebus.windows.net/[event hub name]/publishers/[my publisher name]
You don’t have to create publisher names ahead of time, but they must match the SAS token used when publishing an event, in order to ensure independent publisher identities. When using publisher policies, the PartitionKey value is set to the publisher name. To work properly, these values must match.
Event Hubs Capture enables you to automatically capture the streaming data in Event Hubs and save it to your choice of either a Blob storage account, or an Azure Data Lake Service account. You can enable Capture from the Azure portal, and specify a minimum size and time window to perform the capture. Using Event Hubs Capture, you specify your own Azure Blob Storage account and container, or Azure Data Lake Service account, which is used to store the captured data. Captured data is written in the Apache Avro format.
Event Hubs provides message streaming through a partitioned consumer pattern in which each consumer only reads a specific subset, or partition, of the message stream. This pattern enables horizontal scale for event processing and provides other stream-focused features that are unavailable in queues and topics.
A partition is an ordered sequence of events that is held in an event hub. As newer events arrive, they are added to the end of this sequence. A partition can be thought of as a “commit log.”

Event Hubs retains data for a configured retention time that applies across all partitions in the event hub. Events expire on a time basis; you cannot explicitly delete them. Because partitions are independent and contain their own sequence of data, they often grow at different rates.

The number of partitions is specified at creation and must be between 2 and 32. The partition count is not changeable, so you should consider long-term scale when setting partition count. Partitions are a data organization mechanism that relates to the downstream parallelism required in consuming applications. The number of partitions in an event hub directly relates to the number of concurrent readers you expect to have. You can increase the number of partitions beyond 32 by contacting the Event Hubs team.
While partitions are identifiable and can be sent to directly, sending directly to a partition is not recommended. Instead, you can use higher level constructs introduced in the Event publisher and Capacity sections.
Partitions are filled with a sequence of event data which contains the body of the event, a user-defined property bag, and metadata such as its offset in the partition and its number in the stream sequence.
For more information about partitions and the trade-off between availability and reliability, see the Event Hubs programming guide and the Availability and consistency in Event Hubsarticle.
You can use a partition key to map incoming event data into specific partitions for the purpose of data organization. The partition key is a sender-supplied value passed into an event hub. It is processed through a static hashing function, which creates the partition assignment. If you don’t specify a partition key when publishing an event, a round-robin assignment is used.
The event publisher is only aware of its partition key, not the partition to which the events are published. This decoupling of key and partition insulates the sender from needing to know too much about the downstream processing. A per-device or user unique identity makes a good partition key, but other attributes such as geography can also be used to group related events into a single partition.
Event Hubs uses Shared Access Signatures, which are available at the namespace and event hub level. A SAS token is generated from a SAS key and is an SHA hash of a URL, encoded in a specific format. Using the name of the key (policy) and the token, Event Hubs can regenerate the hash and thus authenticate the sender. Normally, SAS tokens for event publishers are created with only send privileges on a specific event hub. This SAS token URL mechanism is the basis for publisher identification introduced in the publisher policy. For more information about working with SAS, see Shared Access Signature Authentication with Service Bus.
Any entity that reads event data from an event hub is an event consumer. All Event Hubs consumers connect via the AMQP 1.0 session and events are delivered through the session as they become available. The client does not need to poll for data availability.
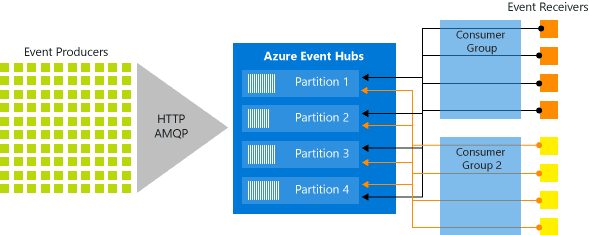
The publish/subscribe mechanism of Event Hubs is enabled through consumer groups. A consumer group is a view (state, position, or offset) of an entire event hub. Consumer groups enable multiple consuming applications to each have a separate view of the event stream, and to read the stream independently at their own pace and with their own offsets.
In a stream processing architecture, each downstream application equates to a consumer group. If you want to write event data to long-term storage, then that storage writer application is a consumer group. Complex event processing can then be performed by another, separate consumer group. You can only access partitions through a consumer group. There can be at most 5 concurrent readers on a partition per consumer group; however it is recommended that there is only one active receiver on a partition per consumer group. There is always a default consumer group in an event hub, and you can create up to 20 consumer groups for a Standard tier event hub.
The following are examples of the consumer group URI convention:
//[my namespace].servicebus.windows.net/[event hub name]/[Consumer Group #1]
//[my namespace].servicebus.windows.net/[event hub name]/[Consumer Group #2]
The following figure shows the Event Hubs stream processing architecture:
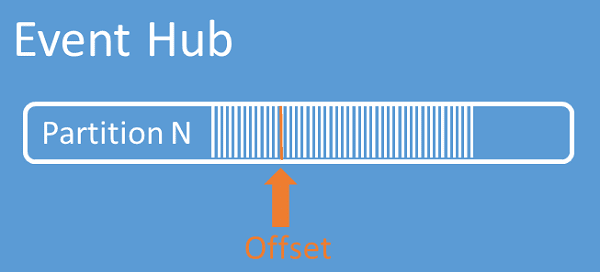
An offset is the position of an event within a partition. You can think of an offset as a client-side cursor. The offset is a byte numbering of the event. This offset enables an event consumer (reader) to specify a point in the event stream from which they want to begin reading events. You can specify the offset as a timestamp or as an offset value. Consumers are responsible for storing their own offset values outside of the Event Hubs service. Within a partition, each event includes an offset.
Checkpointing is a process by which readers mark or commit their position within a partition event sequence. Checkpointing is the responsibility of the consumer and occurs on a per-partition basis within a consumer group. This responsibility means that for each consumer group, each partition reader must keep track of its current position in the event stream, and can inform the service when it considers the data stream complete.
If a reader disconnects from a partition, when it reconnects it begins reading at the checkpoint that was previously submitted by the last reader of that partition in that consumer group. When the reader connects, it passes this offset to the event hub to specify the location at which to start reading. In this way, you can use checkpointing to both mark events as “complete” by downstream applications, and to provide resiliency if a failover between readers running on different machines occurs. It is possible to return to older data by specifying a lower offset from this checkpointing process. Through this mechanism, checkpointing enables both failover resiliency and event stream replay.
All Event Hubs consumers connect via an AMQP 1.0 session, a state-aware bidirectional communication channel. Each partition has an AMQP 1.0 session that facilitates the transport of events segregated by partition.
When connecting to partitions, it is common practice to use a leasing mechanism to coordinate reader connections to specific partitions. This way, it is possible for every partition in a consumer group to have only one active reader. Checkpointing, leasing, and managing readers are simplified by using the EventProcessorHost class for .NET clients. The Event Processor Host is an intelligent consumer agent.
After an AMQP 1.0 session and link is opened for a specific partition, events are delivered to the AMQP 1.0 client by the Event Hubs service. This delivery mechanism enables higher throughput and lower latency than pull-based mechanisms such as HTTP GET. As events are sent to the client, each event data instance contains important metadata such as the offset and sequence number that are used to facilitate checkpointing on the event sequence.
Event data:
It is your responsibility to manage the offset.
Event Hubs has a highly scalable parallel architecture and there are several key factors to consider when sizing and scaling.
The throughput capacity of Event Hubs is controlled by throughput units. Throughput units are pre-purchased units of capacity. A single throughput unit includes the following capacity:
Beyond the capacity of the purchased throughput units, ingress is throttled and a ServerBusyException is returned. Egress does not produce throttling exceptions, but is still limited to the capacity of the purchased throughput units. If you receive publishing rate exceptions or are expecting to see higher egress, be sure to check how many throughput units you have purchased for the namespace. You can manage throughput units on the Scale blade of the namespaces in the Azure portal. You can also manage throughput units programmatically using the Event Hubs APIs.
Throughput units are billed per hour and are pre-purchased. Once purchased, throughput units are billed for a minimum of one hour. Up to 20 throughput units can be purchased for an Event Hubs namespace and are shared across all Event Hubs in the namespace.
More throughput units can be purchased in blocks of 20, up to 100 throughput units, by contacting Azure support. Beyond that, you can also purchase blocks of 100 throughput units.
We recommend that you balance throughput units and partitions to achieve optimal scale. A single partition has a maximum scale of one throughput unit. The number of throughput units should be less than or equal to the number of partitions in an event hub.
For detailed Event Hubs pricing information, see Event Hubs pricing.
Source: What is Azure Event Hubs and why use it | Microsoft Docs

Transforming Enterprises with
Data & AI Services & Solutions.
ThirdEye delivers Data and AI services & solutions for enterprises worldwide by
leveraging state-of-the-art Data & AI technologies.

