Amazon Athena is an interactive query service that makes it easy to analyze data directly in Amazon Simple Storage Service (Amazon S3) using standard SQL. With a few actions in the AWS Management Console, you can point Athena at your data stored in Amazon S3 and begin using standard SQL to run ad-hoc queries and get results in seconds.
Athena is serverless, so there is no infrastructure to set up or manage, and you pay only for the queries you run. Athena scales automatically—executing queries in parallel—so results are fast, even with large datasets and complex queries.
Athena helps you analyze unstructured, semi-structured, and structured data stored in Amazon S3. Examples include CSV, JSON, or columnar data formats such as Apache Parquet and Apache ORC. You can use Athena to run ad-hoc queries using ANSI SQL, without the need to aggregate or load the data into Athena.
Athena integrates with the AWS Glue Data Catalog, which offers a persistent metadata store for your data in Amazon S3. This allows you to create tables and query data in Athena based on a central metadata store available throughout your AWS account and integrated with the ETL and data discovery features of AWS Glue. For more information, see Integration with AWS Glue and What is AWS Glue in the AWS Glue Developer Guide.
Athena integrates with Amazon QuickSight for easy data visualization.
You can use Athena to generate reports or to explore data with business intelligence tools or SQL clients connected with a JDBC or an ODBC driver. For more information, see What is Amazon QuickSight in the Amazon QuickSight User Guide and Connecting to Amazon Athena with ODBC and JDBC Drivers.
You can create named queries with AWS CloudFormation and run them in Athena. Named queries to allow you to map a query name to a query and then call the query multiple times referencing it by its name. For information, see CreateNamedQuery in the Amazon Athena API Reference, and AWS::Athena::NamedQuery in the AWS CloudFormation User Guide.
You can access Athena using the AWS Management Console, through a JDBC connection, using the Athena API, or using the Athena CLI.
aws athena help the command line to see available commands. For information about available commands, see the AWS Athena command line reference.In Athena, tables and databases are containers for the metadata definitions that define a schema for underlying source data. For each dataset, a table needs to exist in Athena. The metadata in the table tells Athena where the data is located in Amazon S3 and specifies the structure of the data, for example, column names, data types, and the name of the table. Databases are a logical grouping of tables, and also hold only metadata and schema information for a dataset.
For each dataset that you’d like to query, Athena must have an underlying table it will use for obtaining and returning query results. Therefore, before querying data, a table must be registered in Athena. The registration occurs when you either create tables automatically or manually.
Regardless of how the tables are created, the tables creation process registers the dataset with Athena. This registration occurs either in the AWS Glue Data Catalog or in the internal Athena data catalog and enables Athena to run queries on the data.
The AWS Glue Data Catalog is accessible throughout your AWS account. Other AWS services can share the AWS Glue Data Catalog, so you can see databases and tables created throughout your organization using Athena and vice versa. In addition, AWS Glue lets you automatically discover data schema and extract, transform, and load (ETL) data.
Note
You use the internal Athena data catalog in regions where AWS Glue is not available and where the AWS Glue Data Catalog cannot be used.
When you create tables and databases manually, Athena uses HiveQL data definition language (DDL) statements such as,CREATE TABLECREATE DATABASE, and underDROP TABLE the hood to create tables and databases in the AWS Glue Data Catalog, or in its internal data catalog in those regions where AWS Glue is not available.
Note
If you have tables in Athena created before August 14, 2017, they were created in an Athena-managed data catalog that exists side-by-side with the AWS Glue Data Catalog until you choose to update. For more information, see Upgrading to the AWS Glue Data Catalog Step-by-Step.
When you query an existing table, under the hood, Amazon Athena uses Presto, a distributed SQL engine. We have examples with sample data within Athena to show you how to create a table and then issue a query against it using Athena. Athena also has a tutorial in the console that helps you get started creating a table based on data that is stored on Amazon S3.
You first need to create a database in Athena.
To create a database
mydatabase, enter the following CREATE DATABASE statement, and then choose Run Query:
CREATE DATABASE mydatabasemydatabase appears in the DATABASE list in the Catalog dashboard on the left side.
Now that you have a database, you’re ready to create a table that’s based on the sample data file. You define columns that map to the data, specify how the data is delimited, and provide the location in Amazon S3 for the file.
To create a table
mydatabase selected for DATABASE and then choose New Query.Note
You can query data in regions other than the region where you run Athena. Standard inter-region data transfer rates for Amazon S3 apply in addition to standard Athena charges. To reduce data transfer charges, replace my region in s3://athena-examples-myregion/path/to/data/ with the region identifier where you run Athena, for example,s3://athena-examples-us-east-1/path/to/data/
CREATE EXTERNAL TABLE IF NOT EXISTS cloudfront_logs (
`Date` DATE,
Time STRING,
Location STRING,
Bytes INT,
RequestIP STRING,
Method STRING,
Host STRING,
Uri STRING,
Status INT,
Referrer STRING,
os STRING,
Browser STRING,
BrowserVersion STRING
) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "^(?!#)([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+[^\(]+[\(]([^\;]+).*\%20([^\/]+)[\/](.*)$"
) LOCATION 's3://athena-examples-myregion/cloudfront/plaintext/';The istable cloudfront_logs created and appears in the Catalog dashboard for your database.
Now that you have the tablecloudfront_logs created in Athena based on the data in Amazon S3, you can run queries on the table and see the results in Athena.
To run a query
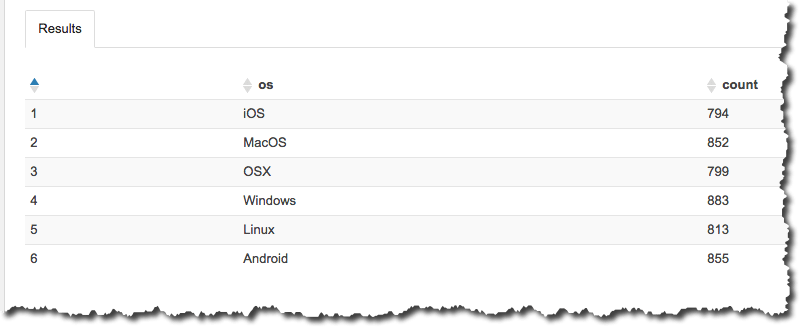
SELECT os, COUNT(*) count
FROM cloudfront_logs
WHERE date BETWEEN date '2014-07-05' AND date '2014-08-05'
GROUP BY os;Results are returned that look like the following:
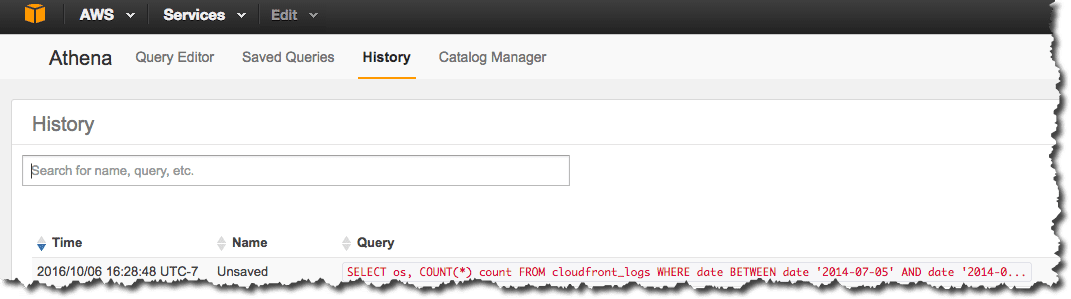
You can also view the results of previous queries or queries that may take some time to complete. Choose History then either search for your query or choose View or Download to view or download the results of previously completed queries. This also displays the status of queries that are currently running. Query history is retained for 45 days. For information, see Viewing Query History.
Query results are also stored in Amazon S3 in a bucket called aws-athena-query-results-ACCOUNTID–REGION. You can change the default location in the console and encryption options by choosing Settings in the upper right pane. For more information, see Query Results.
AWS Glue is a fully managed ETL (extract, transform, and load) service that can categorize your data, clean it, enrich it, and move it reliably between various data stores. AWS Glue crawlers automatically infer database and table schema from your source data, storing the associated metadata in the AWS Glue Data Catalog. When you create a table in Athena, you can choose to create it using an AWS Glue crawler.
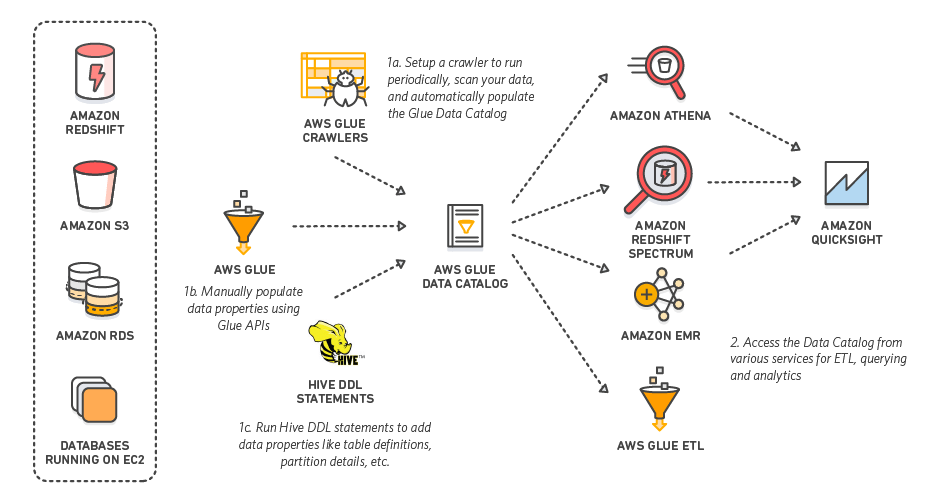
In regions where AWS Glue is supported, Athena uses the AWS Glue Data Catalog as a central location to store and retrieve table metadata throughout an AWS account. The Athena execution engine requires table metadata that instructs it where to read data, how to read it, and other information necessary to process the data. The AWS Glue Data Catalog provides a unified metadata repository across a variety of data sources and data formats, integrating not only with Athena, but with Amazon S3, Amazon RDS, Amazon Redshift, Amazon Redshift Spectrum, Amazon EMR, and any application compatible with the Apache Hive metastore.

Transforming Enterprises with
Data & AI Services & Solutions.
ThirdEye delivers Data and AI services & solutions for enterprises worldwide by
leveraging state-of-the-art Data & AI technologies.

